社区
C#
帖子详情
tesseract文字识别率挺高的,但这张图片怎么就认不出来?
r00_a2lBUR
2017-09-15 04:51:43
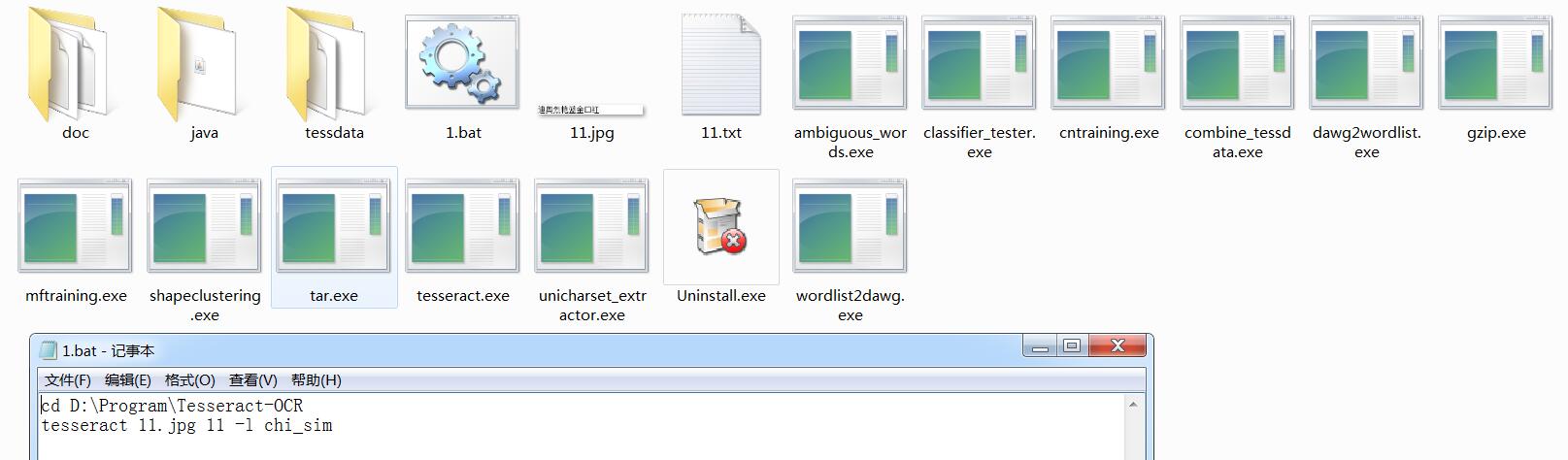
我用C#做一个bat文件并且运行,然后读取生成的txt文件方法实现图片的汉字识别,识别率还挺高的。不过这张图片怎么就认不出来?
用的是tesseract-ocr-setup-3.02.02安装包安装,网上下载的一个中文语言包:
...全文
1423
1
打赏
收藏
tesseract文字识别率挺高的,但这张图片怎么就认不出来?
我用C#做一个bat文件并且运行,然后读取生成的txt文件方法实现图片的汉字识别,识别率还挺高的。不过这张图片怎么就认不出来? 用的是tesseract-ocr-setup-3.02.02安装包安装,网上下载的一个中文语言包:
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
_乾坤_
2017-10-14
打赏
举报
回复
可以将边上的框去掉再识别,可能就可以了。
c#实现基于
tesseract
的ocr识别
c#实现基于
tesseract
的ocr识别 ,二值化
图片
效果好
tesseract
-ocr实现
图片
识别功能(java)
一个Google支持的开源的OCR图文识别开源项目。去持多语言(当前3.02 版本支持包括英文,简体中文,繁体中文),支持Windows,Linux,Mac OSX 多平台。使用中
Tesseract
的识别
率
非常
高
。可以参考网上的相关资料进行对
Tesseract
字符识别进行样本训练,通过使用训练后的语言库会提
高
识别精度。
Tesseract
-OCR.zip
图片
文字识别
无需安装,直接解压即可
内含详细操作过程, 萌新,不会代码也能上手。
Tesseract
-OCR识别中文文字
图片
绕过pytesser,直接使用
Tesseract
-OCR进行中文文字的识别,识别
率
相对较低,后续会上传优化版本
tesseract
-ocr- 的字母数字识别
速度比较的快了,很不错的资源,可以识别字母和数字。
C#
111,120
社区成员
642,537
社区内容
发帖
与我相关
我的任务
C#
.NET技术 C#
复制链接
扫一扫
分享
社区描述
.NET技术 C#
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧
+ 用AI写文章
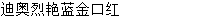



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


