sqlserver 数据库的排序规则和操作系统的语言环境是什么关系?
又晕了,问题都描述不清楚了
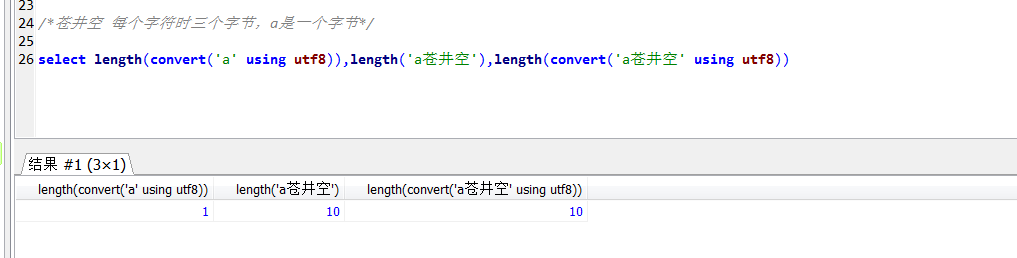
sqlserver的排序规则包含了字符集,因此说排序规则就隐含了字符集(这句话对吧)。
只是还没想明白,
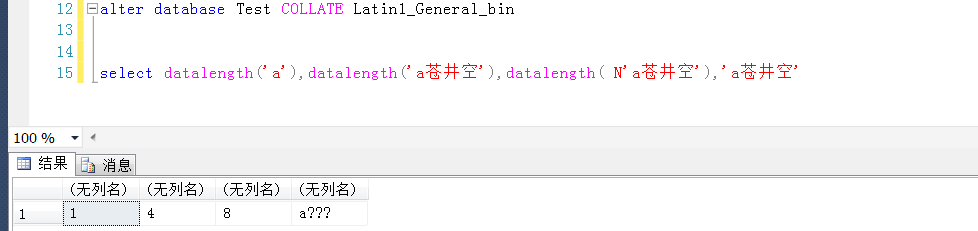
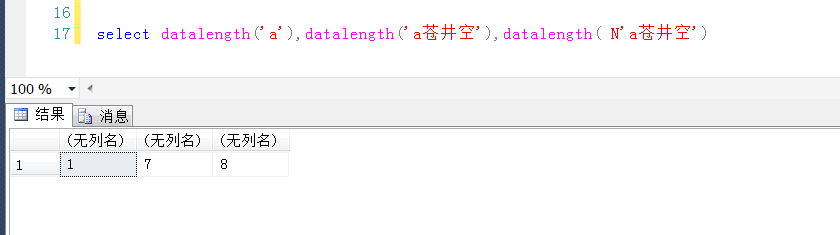
1,当数据库的排序规则是Chinese_PRC_CI_AS的时候,varchar或者char类型可以正常存储汉字
那不是说明varchar也可以支持汉字?那换到别的操作系统上,就有可能有问题了,这是为什么?
当数据库的排序规则是Latin1_General_BIN的时候,varchar或者char类型无法正常存储汉字,又是为什么?
2,Latin1_General_BIN与Latin1_General_CS_AS都是区分大小写的,那么区别是什么?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享