社区
HTML/XML
帖子详情
Html parser 取不出标签内的内容
代斯Max
2017-09-19 05:18:49
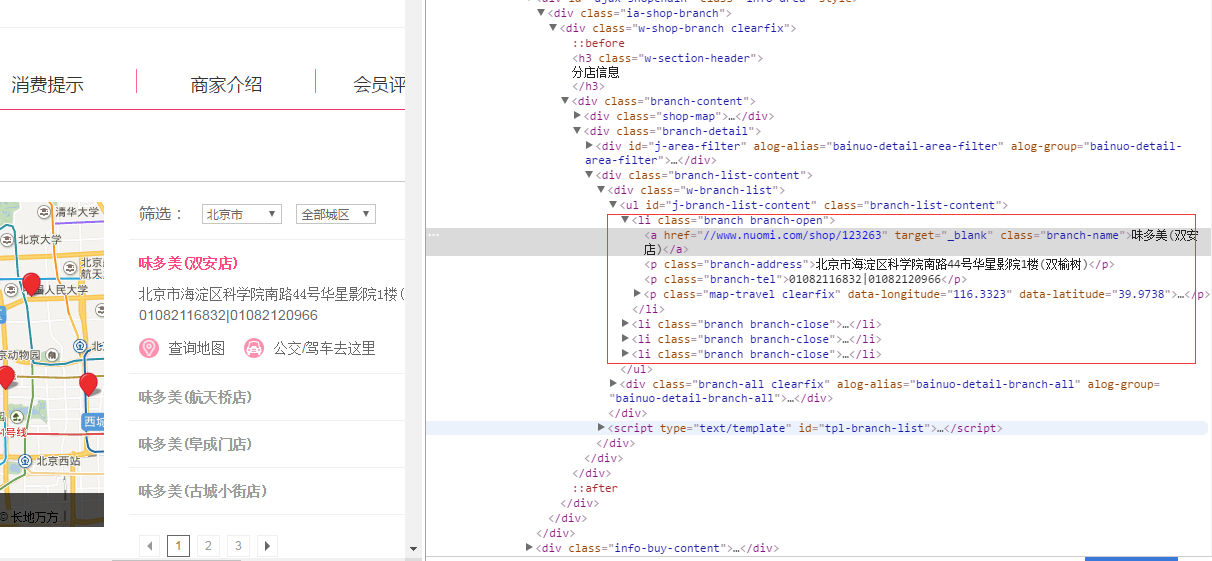
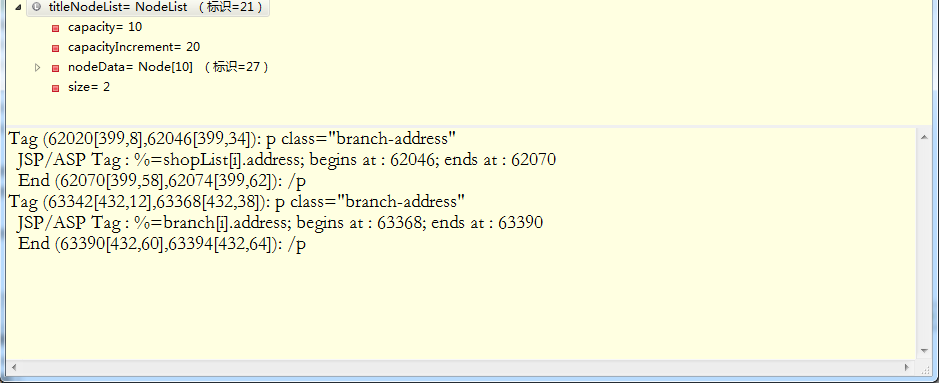
想爬取地址数据,方法都是对的,但想取的内容就像不对外开放似的。就说这个地址branch-address,script内的内容取出来了,li标签内的数据取不出来,为什么?
...全文
409
2
打赏
收藏
Html parser 取不出标签内的内容
想爬取地址数据,方法都是对的,但想取的内容就像不对外开放似的。就说这个地址branch-address,script内的内容取出来了,li标签内的数据取不出来,为什么?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
代斯Max
2017-09-19
打赏
举报
回复
引用 1 楼 oyljerry 的回复:
一般是ajax异步返回的内容,它是js动态插入的
谢谢,这样有解决的方法吗?
oyljerry
2017-09-19
打赏
举报
回复
一般是ajax异步返回的内容,它是js动态插入的
关于
Html
Parser
提取
标签
不完整的问题(
Html
Parser
扩展)
而遇到它不认识的
标签
时提取出来的
内容
只会是这个
标签
的开始
标签
.例如有段
Html
是加粗字体 ,如果用NodeList nodeList =
parser
.
parser
(new TagNameFilter("strong"));提取的话结果就是 .如果想让提取结果是完整的加粗...
python3 读取
html
文件,关于Python3.7的BeautifulSoup解析
html
文件缺失
内容
的问题
背景从网站爬取
html
,用BeautifulSoup解析
标签
内容
,发现用尽办法都找不到想要的
标签
。分析过程(1)把urlopen请求到的
html
打印出来,body是完整的;(2)把BeautifulSoup解析后的soup打印出来,body只有少量的div,很快...
python爬虫代码没有结果_beautifulsoup - python爬虫获取不到
标签
内容
问 题链接如下:http://aaxxy.com/vod-detail-i...使用requests请求此连接,然后用BeautifulSoup解析获取 dl > dd > a
标签
的
内容
,其中:上图所示的4个 a
标签
的
内容
只能获取到第一个“电影”,后面三个“动作”...
Pure-JavaScript-
HTML
5-
Parser
源码解读
有个需求要用到
html
标签
解析,又碰巧之前有人写过,就直接用了之前用的东西https://github.com/blowsie/Pure-JavaScript-
HTML
5-
Parser
,git上星不多,不过感觉思路比较特别,和我最开始想的不太一样,稍微看了看原理...
python爬不是网页_用python爬网站数据,为什么只爬到
标签
,爬不到
标签
内容
呢
怎么弄也没有,跪求解决办法 谢谢 谢谢 谢谢 解决方案 因为你需要的数据是有ajax动态生成的,在
html
源码中是找不到的,所以需要能够动态加载js工具,你可以用这个 selenium+PhantomJS来执行js的
内容
,不过这个相对来...
HTML/XML
3,055
社区成员
8,066
社区内容
发帖
与我相关
我的任务
HTML/XML
VC/MFC HTML/XML
复制链接
扫一扫
分享
社区描述
VC/MFC HTML/XML
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享