社区
脚本语言
帖子详情
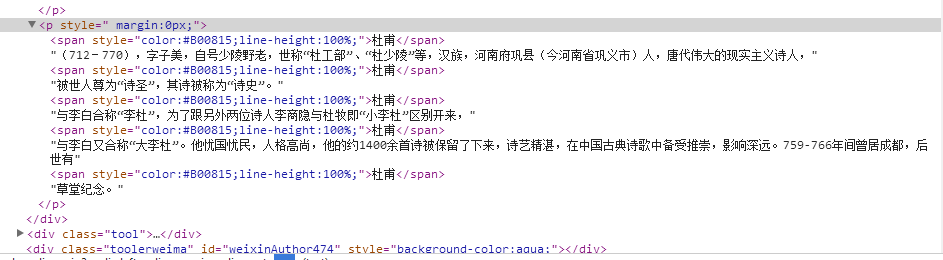
新手--Python爬虫请问一下这个怎么爬取?
huanan0581
2017-10-08 10:02:29
请问一下各位大神,我该怎么获取两个<span>xx</span>........<span>XX</span>获取XX也获取.....中的内容!
谢谢了~
...全文
282
5
打赏
收藏
新手--Python爬虫请问一下这个怎么爬取?
请问一下各位大神,我该怎么获取两个xx........XX获取XX也获取.....中的内容! 谢谢了~
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
lwghost
2017-11-02
打赏
举报
回复
from bs4 import BeautifulSoup import urllib.request def GetURL(url): html=urllib.request.urlopen(url) soup=BeautifulSoup(html) ls=soup.find_all('p') for l in ls: s=l.find_all('span') print(s)
LOWGUN
2017-10-15
打赏
举报
回复
reg = r'<span style="color:#B00815.............>(.*?)" </span>' name = re.findall(reg, html)
暗里着迷0902
2017-10-11
打赏
举报
回复
用scrapy模块,里面用xpath+正则解析就可以了
nageyes
2017-10-09
打赏
举报
回复
学了正则表达式就简单好多呢
qq852053457
2017-10-09
打赏
举报
回复
lxml模块里面有个tail 可以获取节点之后的内容 http://blog.csdn.net/betabin/article/details/24392369
Python
爬虫
入门:如何
爬取
招聘网站并进行分析
python
爬虫
实操干货,一分钟了解全国行业工资水平,适合
新手
,数据抓取、清洗、结果分析一步到位,快快行动起来
python
城市降雨量
爬取
(数据
爬取
).zip
使用
python
爬取
天气的数据,并将数据打印出来,主要数据为各个省会城市的降雨量,可以根据具体需求更改。本资源适合
新手
小白和在校学生,使用前请务必查看说明文档 #资源达人分享计划#
4小时学会
Python
网络
爬虫
-CEO带你
爬取
猫眼电影教程
4小时学会
Python
爬虫
视频培训教程,从
Python
爬虫
...课程具体有:
python
基础语法、运算符、数据类型、流程控制、函数定义和使用、正则表达式、requests
爬虫
库的使用、以及最后可以独立完成一个网络
爬虫
案例实战。
基于
Python
爬虫
的股票信息
爬取
保存到文件
自己做的一个课程设计。含源码,含实验报告! 能够
爬取
网站的股票信息, 列成一张信息表,保存到txt文件,也可以保存到excel表 虽然感觉有点low,我也是
新手
,学习中! 精心设计,求好评!
python
代码自动办公
Python
爬虫
爬取
会计师协会网站的指定文章项目源码有详细注解,适合
新手
一看就懂.rar
python
代码自动办公
Python
爬虫
爬取
会计师协会网站的指定文章项目源码有详细注解,适合
新手
一看就懂
脚本语言
37,719
社区成员
34,238
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享