3,425
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
from urllib.request import urlopen
from bs4 import BeautifulSoup
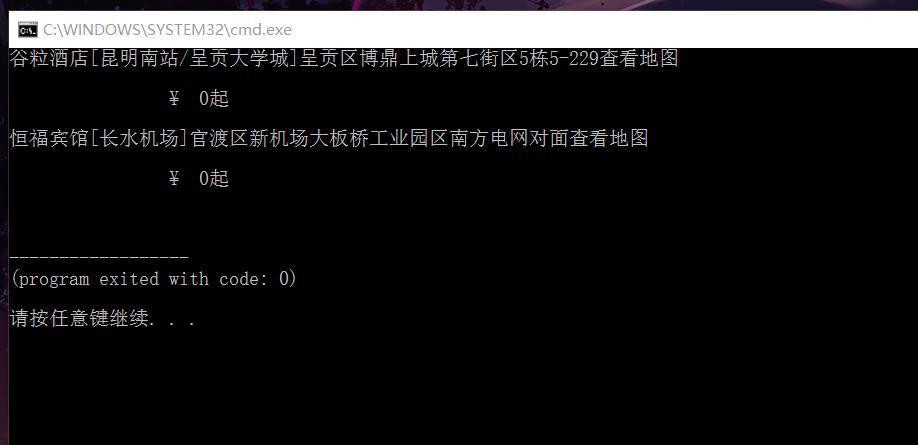
lii=["http://hotel.meituan.com/item/161066061/?ci=2017-10-20&co=2017-10-21","http://hotel.meituan.com/item/5651700/?ci=2017-10-20&co=2017-10-21"]
for ss in lii:
url=urlopen(ss)
soup=BeautifulSoup(url.read(),"lxml")
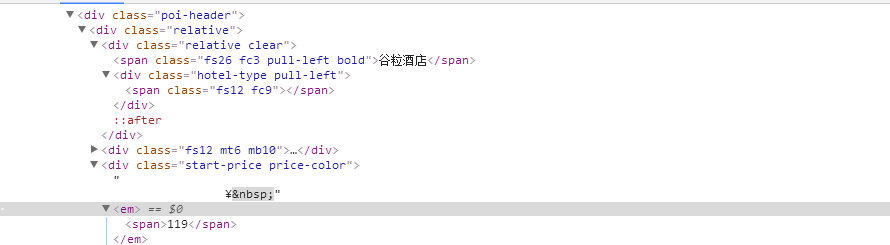
ui=soup.find_all("span",{"class":"fs26 fc3 pull-left bold"})
score=soup.select("#poiDetail > div > div > div.base-info > div > div.relative")
for name in score:
print(name.get_text())
from requests_html import HTMLSession
session = HTMLSession()
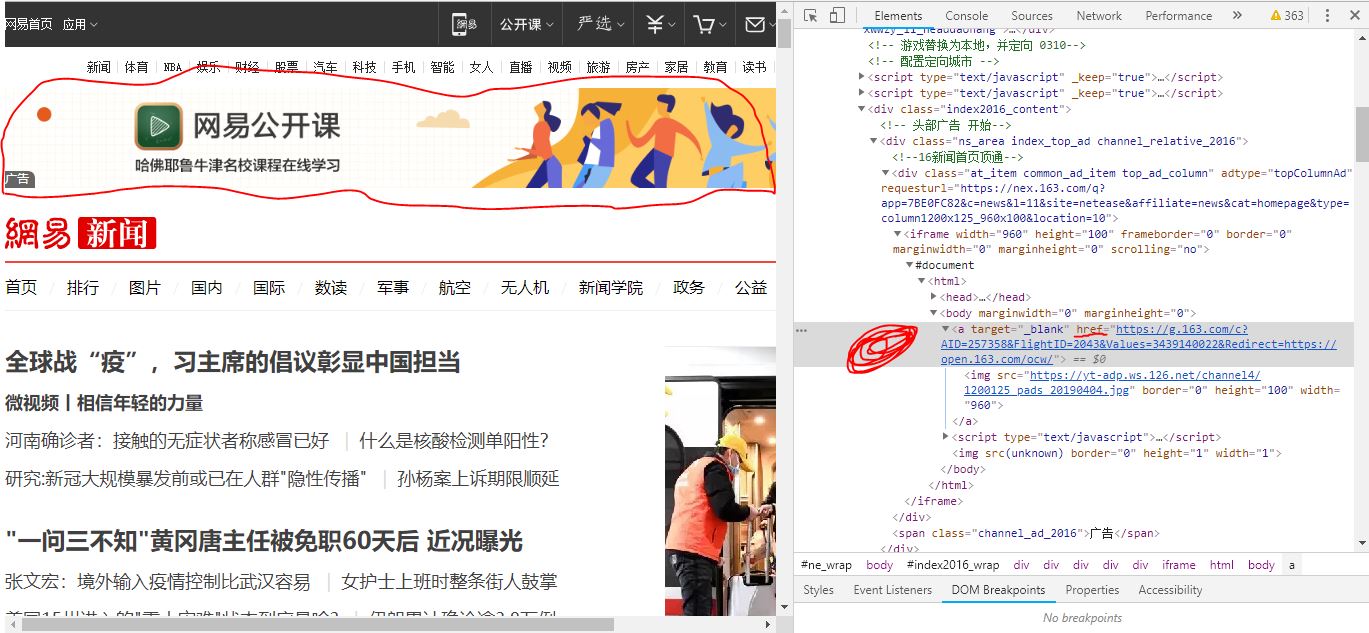
url = 'https://news.163.com/'
r = session.get(url)
sel='//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[1]/div/iframe/html/body/a'
results = r.html.xpath(sel)
print(results.html.text)