

65,211
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
#include <iostream>
#include <regex>
#include <string>
using namespace std;
int main() {
string str;
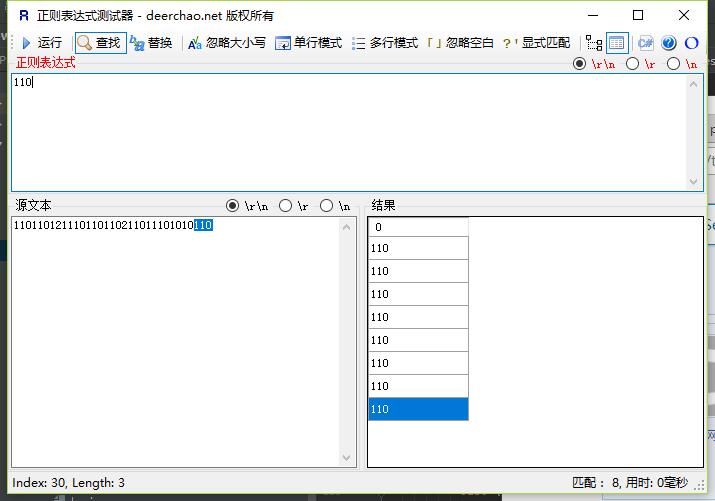
str = "110110121110110110211011101010110";
regex reg("\\b(110)([^ ]*)");
std::smatch sm; // same as std::match_results<string::const_iterator> sm;
if (regex_match(str, reg))
cout << "string object matched\n";
regex_match(str, sm, reg);
cout << "string object with " << sm.size() << " matches\n";
for (int i = 0; i < sm.size(); i++) {
cout << (sm[i]) << endl;
}
return 0;
}

// regex_search example
#include <iostream>
#include <string>
#include <regex>
int main()
{
std::string s("this subject has a submarine as a subsequence");
std::smatch m;
std::regex e("\\b(sub)([^ ]*)"); // matches words beginning by "sub" //GCC未支持
std::cout << "目标序列: " << s << std::endl;
std::cout << "正则公式: /\\b(sub)([^ ]*)/" << std::endl;
std::cout << "The following matches and submatches were found:" << std::endl;
while (std::regex_search(s, m, e)) {
// 输出方式1
for (auto i = 0 ; i != m.size() ; ++i)
std::cout << m[i] << " ";
std::cout << std::endl;
// 输出方式2
for (auto it = m.begin() ; it != m.end() ; ++it)
std::cout << *it << " ";
std::cout << std::endl;
// for (auto x:m) std::cout << x << " "; // VC2010 不支持
// 格式化输出
std::cout << m.format("公式匹配: [$0].\n");
std::cout << m.format("子公司S1和S2匹配: [$1] and [$2].\n\n");
s = m.suffix().str(); // 返回末端,作为新的搜索的开始
}
return 0;
}
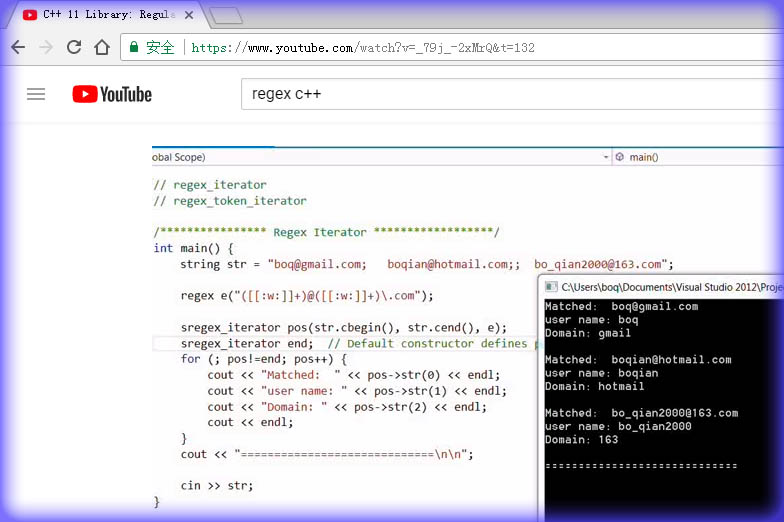
https://www.youtube.com/watch?v=_79j_-2xMrQ&t=132#include <iostream>
#include <sstream>
#include <fstream>
#include <string>
#include <regex>
using namespace std;
int main()
{
ifstream infile("main.cpp"); // 对本CPP源文件处理
ofstream fcout("OK.html");
stringstream oss;
oss << infile.rdbuf();
string s(oss.str());
regex reg_beg("<a href=\"http://topic\\.csdn\\.net"); // 匹配 <a href="http://topic.csdn.net
regex reg_end("</a>");
smatch m;
smatch m2;
string::const_iterator it = s.begin();
string::const_iterator end = s.end();
while (regex_search(it, end, m, reg_beg)) { // 以迭代器区间搜索正则式
it = m[0].second; // 前次匹配的末尾迭代器传给it,当下次搜索搜索的开始
if (regex_search(m[0].first, end, m2, reg_end))
fcout << string(m[0].first, m2[0].second) << "<p>" << endl;
cout << string(m[0].first, m2[0].second) << "<p>" << endl;
}
infile.close(); fcout.close();
return 0;
}
#if(0) // 示例 HTML文本
{
<a href="http://topic.csdn.net/u/20111116/11/96be7f40-497f-4ab6-aacc-d3391bbbf237.html"
target="_blank">
学习分享:C++ 00x直接使用boost正则使用方法
</a><p>
<a href="http://topic.csdn.net/u/20110831/18/07df11c3-817f-4163-b092-e8fc04d34137.html"
target="_blank">
发个简单的代码,因为很多人 分不清char c[] 和 char *c
</a><p>
<a href="http://topic.csdn.net/u/20110328/19/ace9d89a-88c7-4721-9d83-574b56c7564b.html"
target="_blank">
Code::BLOCKS 语法高亮 C/C++ 标准库 NAMESPACE STD WinAPI WX_API
</a><p>
}
#endif



