社区
Hadoop生态社区
帖子详情
scala-2.12.3+hadoop-2.7.4+spark-2.2.0
Wendy010101
2017-10-25 03:16:55
spark 启动不了
spark-env.sh
export JAVA_HOME=...........
export SCALA_HOME=.............
export HADOOP_CONF_DIR=........
slaves
localhost
/etc/profile
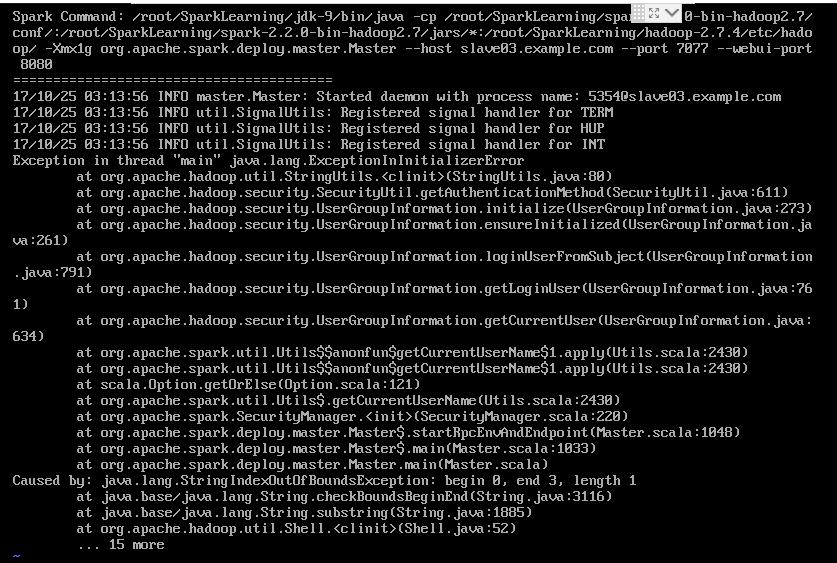
错误日志
...全文
411
1
打赏
收藏
scala-2.12.3+hadoop-2.7.4+spark-2.2.0
spark 启动不了 spark-env.sh export JAVA_HOME=........... export SCALA_HOME=............. export HADOOP_CONF_DIR=........ slaves localhost /etc/profile 错误日志
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Wendy010101
2017-10-26
打赏
举报
回复
spark 不支持java 9, 换成java 8 就解决了
spark
环境安装(
Hadoop
HA+Hbase+phoneix+kafka+flume+zookeeper+
spark
+
scala
)
亲手在Centos7上安装,所用软件列表 apache-flume-1.8.0-bin.tar.gz apache-phoenix-4.13.0-HBase-1.3-bin.tar.gz
hadoop
-
2.7
.4.tar.gz hbase-1.3.1-bin.tar.gz jdk-8u144-linux-x64.tar.gz kafka_
2.12
-1.0.0.tgz
scala
-
2.12
.4.tar.gz
scala
-
2.12
.4.tgz
spark
-
2.2
.0-bin-
hadoop
2.7
.tgz
spark
-
2.2
.0.tgz zookeeper-3.4.11.tar.gz
Spark
项目之环境搭建(单机)三
scala
-
2.12
.7+
spark
-2.3.2-bin-
hadoop
2.7
安装
上传
scala
和
spark
架包
scala
官网下载:https://www.
scala
-lang.org/download/
spark
官网下载:http://
spark
.apache.org/downloads.html 解压然后重命名 tar -zxf
scala
-
2.12
.7.tgz mv
scala
-
2.12
.7
scala
tar -zxf
spark
-2.3...
【
scala
+
spark
+
hadoop
+idea】踩坑记
昨天装了一天,出现各种问题,比如版本不对应,
hadoop
的配置文件修改错误等等,我出现了问题照着网上的教程一步步走,最终还是死在了
spark
版本应该改低点【传送门】的问题上,这个问题我没有找到其他的解决方法,所以今天我把他们全部卸载重新配置一遍,记录自己遇到的问题供大家参考。 参考教程:milkboylyf写的博客【传送门】 0:安装材料: (1) jdk-8u171-windows-x64 (2)
scala
-2.11.8 (3)
spark
-2.3.1-bin-
hadoop
2.7
.rar (4) had
Spark
之路:(一)
Scala
+
Spark
+
Hadoop
环境搭建
一、
Spark
介绍
Spark
是基于内存计算的大数据分布式计算框架。
Spark
基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将
Spark
部署在大量廉价硬件之上,形成集群。 1.提供分布式计算功能,将分布式存储的数据读入,同时将任务分发到各个节点进行计算; 2.基于内存计算,将磁盘数据读入内存,将计算的中间结果保存在内存,这样可以很好的进
Spark
简单介绍,Windows下安装
Scala
+
Hadoop
+
Spark
运行环境,集成到IDEA中【踩坑成功版】
近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面!
Hadoop
Spark
Flink小编也只知道这些了,由于
Hadoop
,存在一定的缺陷(循环迭代式数据流处理:多并行运行的数据可复用场景效率不行)。所以
Spark
出来了,一匹黑马,8个月的时间从加入Apache,直接成为顶级项目!!选择
Spark
的主要原因是:
Spark
和
Hadoop
的根本差异是多个作业之间的数据通信问题 :
Spark
多个作业之间数据通信是基于内存,而
Hadoop
是基于磁盘。
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

