34,876
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



--测试数据
if not object_id(N'Tempdb..#A') is null
drop table #A
Go
Create table #A([id] nvarchar(22),[title] nvarchar(22))
Insert #A
select N'a1',N'a1' union ALL
SELECT N'b1',N'b1'
GO
if not object_id(N'Tempdb..#B') is null
drop table #B
Go
Create table #B([id] nvarchar(22),[Aid] nvarchar(22),[name] nvarchar(21),[time] Date)
Insert #B
select N'b1',N'a1',N'u','2017-5-6' union all
select N'b2',N'a1',N'x','2017-7-8' union all
select N'b3',N'a1',N'z','2017-2-9'
Go
--测试数据结束
;WITH cte AS (
SELECT * ,
ROW_NUMBER() OVER ( PARTITION BY Aid ORDER BY time DESC ) AS num
FROM #B
)
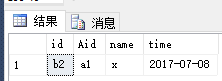
SELECT #A.id ,
cte.Aid ,
cte.name ,
cte.time
FROM #A
LEFT JOIN cte ON #A.id = cte.Aid AND cte.num = 1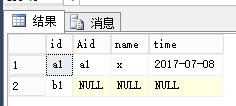
--测试数据
if not object_id(N'Tempdb..#A') is null
drop table #A
Go
Create table #A([id] nvarchar(22),[title] nvarchar(22))
Insert #A
select N'a1',N'a1'
GO
if not object_id(N'Tempdb..#B') is null
drop table #B
Go
Create table #B([id] nvarchar(22),[Aid] nvarchar(22),[name] nvarchar(21),[time] Date)
Insert #B
select N'b1',N'a1',N'u','2017-5-6' union all
select N'b2',N'a1',N'x','2017-7-8' union all
select N'b3',N'a1',N'z','2017-2-9'
Go
--测试数据结束
;WITH cte AS (
SELECT * ,
ROW_NUMBER() OVER ( PARTITION BY Aid ORDER BY time DESC ) AS num
FROM #B
)
SELECT cte.id ,
cte.Aid ,
cte.name ,
cte.time
FROM cte
JOIN #A ON #A.id = cte.Aid
WHERE cte.num = 1;