入门Hadoop-2.x后,可能有HBase需求,所以预先进行了HBase的搭建和使用测试,在测试过程中(Windows Eclipse开发环境下使用JavaAPI访问HBase)发现了一个问题:访问HBase很慢,需要20s左右!具体请看以下说明。【虽说HBase并非能实现实时性很严格的读取,但是其还是具有一定程度的实时读取性能的】
0、Hadoop-2.x测试环境:
0.1)版本: Hadoop-2.7.4 、 HBase-1.2.6 、 zookeeper-3.4.10 (服务器操作系统为 CentOS 6.5 x64)
0.2)搭建模式:完全分布式搭建(由3个节点组成:master 【NameNode、ResourceManager、Hmaster】、slave1【DataNode】 、slave2【DataNode】)
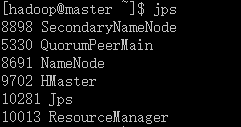
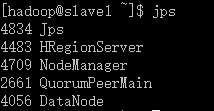
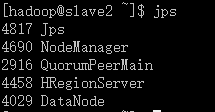
0.3 ) 各节点上的进程服务启动状态:
master:
slave1:
slave2:
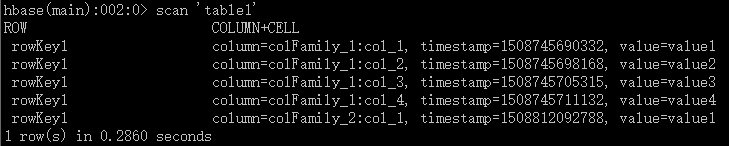
0.4)用本地HBase Shell展示将要用JavaAPI访问的表“table1”内容:
1、Windows Eclipse 的Java程序相关代码:
项目目录:
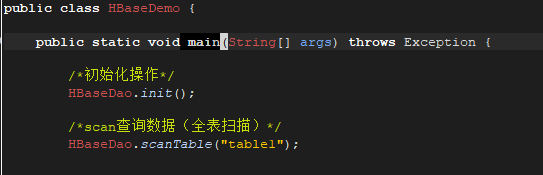
测试类(主程序入口):
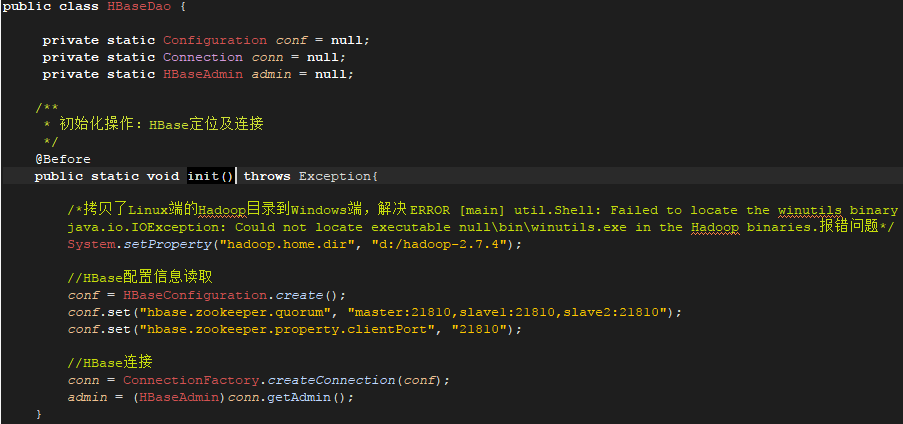
访问HBase的工具类HBaseDao:
初始化HBase连接:
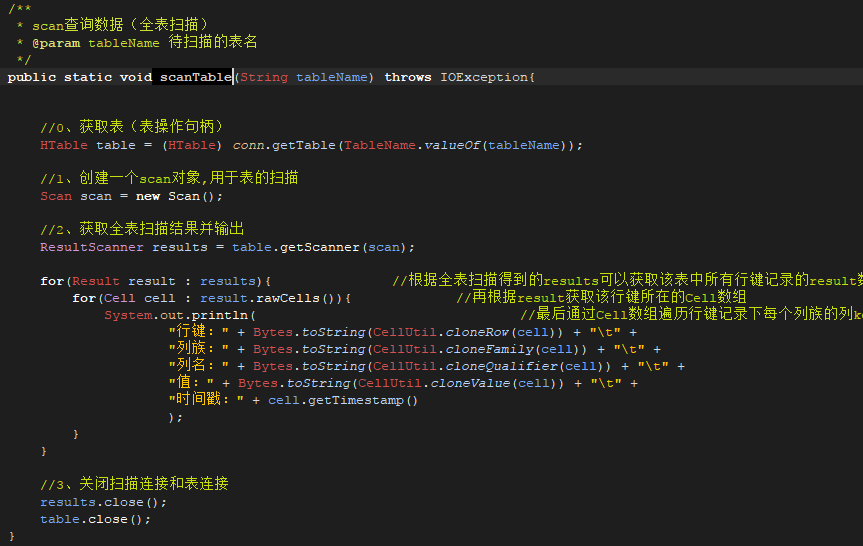
HBase表查询:
2、程序运行(控制台输出):
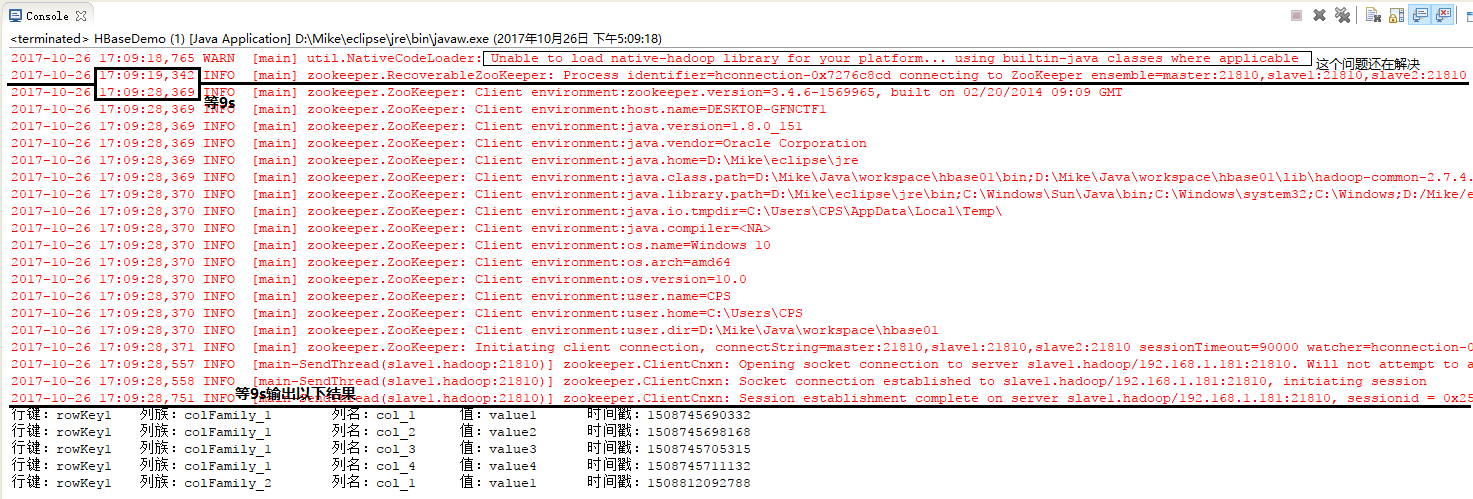
所有的HBase操作都需要至少等待以上划线处的2个“9s”,在网上也有人和我一样需要等待2个9s,但是目前未能找出导致2个9s的问题在哪?以及如何解决?望闻CSDN大神多,还请多多指教,不胜感激啊!!


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




