

34,835
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
USE tempdb
GO
IF OBJECT_ID('t') IS NOT NULL DROP TABLE t
GO
CREATE TABLE t(
[姓名] nvarchar(10)
,[学校] NVARCHAR(10)
,[年级] NVARCHAR(10)
,[缴费记录] int
,[欠费金额] int
,[地址] NVARCHAR(10)
)
GO
INSERT INTO t
SELECT '小明','一小','一','10','1','广东'
UNION SELECT '小明','一小','一','10','1','广州'
UNION SELECT '小红','二小','二','20','2','上海'
UNION SELECT '小华','一小','一','30','3','重庆'
SELECT [姓名],[学校],[年级]
,SUM([缴费记录]) [缴费记录]
,SUM([欠费金额]) [欠费金额]
,MAX([地址]) [地址]
FROM t GROUP BY [姓名],[学校],[年级]
/*
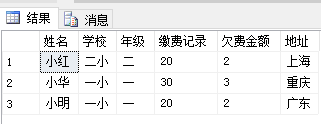
姓名 学校 年级 缴费记录 欠费金额 地址
---------- ---------- ---------- ----------- ----------- ----------
小红 二小 二 20 2 上海
小华 一小 一 30 3 重庆
小明 一小 一 20 2 广州
*/
--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([姓名] nvarchar(22),[学校] nvarchar(22),[年级] nvarchar(21),[缴费记录] int,[欠费金额] int,[地址] nvarchar(22))
Insert #T
select N'小明',N'一小',N'一',10,1,N'广东' union all
select N'小明',N'一小',N'一',10,1,N'广州' union all
select N'小红',N'二小',N'二',20,2,N'上海' union all
select N'小华',N'一小',N'一',30,3,N'重庆'
Go
--测试数据结束
;WITH cte AS (
SELECT 姓名, 学校, 年级 ,
SUM(缴费记录) OVER ( PARTITION BY 姓名, 学校, 年级 ) AS 缴费记录 ,
SUM(欠费金额) OVER ( PARTITION BY 姓名, 学校, 年级 ) AS 欠费金额 ,
ROW_NUMBER() OVER ( PARTITION BY 姓名, 学校, 年级 ORDER BY 地址 ) AS rn,
地址
FROM #T
)
SELECT 姓名 ,
学校 ,
年级 ,
缴费记录 ,
欠费金额 ,
地址
FROM cte
WHERE cte.rn = 1;


 等着大家来帮忙
等着大家来帮忙
