社区
Hadoop生态社区
帖子详情
关于windows 运行 tablemapper的问题
洛轩丶
2017-11-02 10:37:43
在windows 上写了一个mapreduce 程序 map继承的是tablemapper, 做一个简单的查询Hbase 的测试,但是报错,代码和错误信息如下,新人求指教
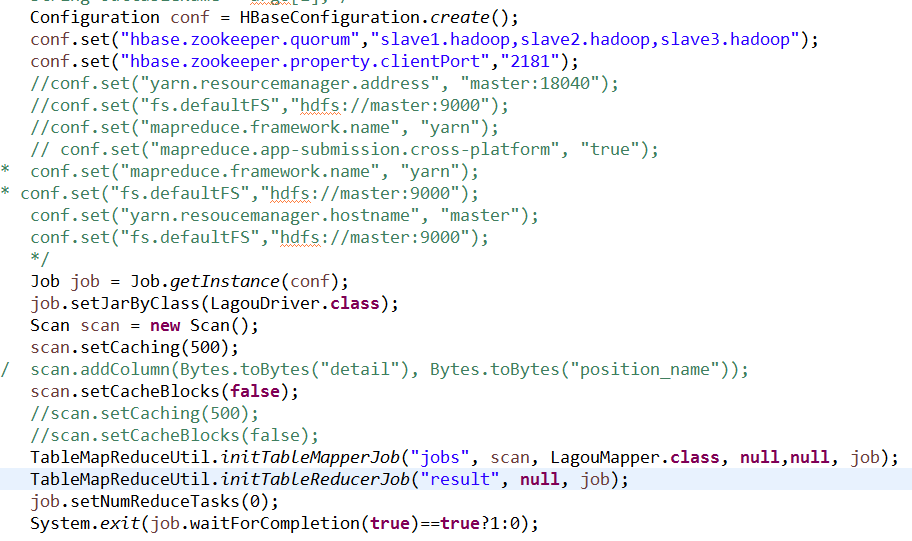
job的代码
map的代码仅仅只是一个输出
集群和hbase 都是普通的配置;大部分都采用默认的设置
windows上面有hadoop编译后能够运行的版本,能够运行一般的mapreduce程序。
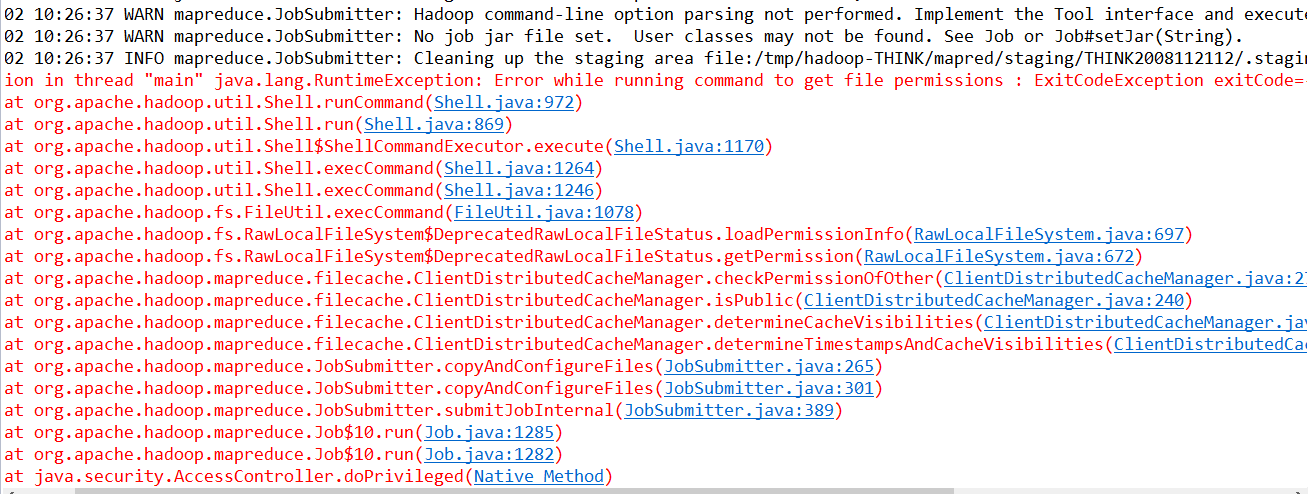
报错信息如下:
这种错误如何解决?
...全文
305
回复
打赏
收藏
关于windows 运行 tablemapper的问题
在windows 上写了一个mapreduce 程序 map继承的是tablemapper, 做一个简单的查询Hbase 的测试,但是报错,代码和错误信息如下,新人求指教 job的代码 map的代码仅仅只是一个输出 集群和hbase 都是普通的配置;大部分都采用默认的设置 windows上面有hadoop编译后能够运行的版本,能够运行一般的mapreduce程序。 报错信息如下: 这种错误如何解决?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Delphi 13.1控件之《AVP虚拟化系统》简要使用手册图片显示完整版.rar
Delphi 13.1控件之《AVP虚拟化系统》简要使用手册图片显示完整版.rar
中国风PPT模板,共9个
中国风PPT模板,共9个
超导磁能储存系统的建模和仿真(Simulink仿真实现)
内容概要:本文围绕超导磁能储存系统(SMES)的建模与仿真展开,基于Simulink平台构建系统级动态仿真模型,涵盖超导线圈、功率转换系统(PCS)以及核心控制策略等关键模块。研究重点在于分析SMES在电网中实现快速能量存储与释放的能力,验证其在提升电力系统稳定性、抑制功率波动方面的有效性,尤其针对新能源发电带来的间歇性与波动性
问题
提供了有效的解决方案。通过仿真手段深入探讨系统的动态响应特性,为优化控制算法的设计与应用提供可靠的技术支撑。; 适合人群:适用于具备电力系统、自动控制理论或能源存储技术背景,熟悉Simulink仿真环境的科研人员、工程技术人员及研究生;同时适合有志于开展新型储能技术仿真研究的高年级本科生参考学习。; 使用场景及目标:①深入理解超导磁能储存系统的基本结构、工作原理及其在电力系统中的应用场景;②掌握在Simulink中搭建复杂电力电子与控制系统联合仿真模型的方法;③研究SMES在电网调频、电压支撑、瞬时功率补偿等典型工况下的动态性能表现;④为后续先进控制策略(如PID、模糊控制、现代控制理论等)的优化设计与验证提供仿真试验平台。; 阅读建议:建议读者结合文中模型逐步动手搭建仿真系统,重点关注各功能模块的参数设置与信号接口匹配,配合具体案例进行仿真调试,深入理解控制逻辑与系统动态行为之间的内在联系,并可进一步拓展至与其他储能形式(如锂电池、飞轮储能)的性能对比研究,以深化对不同类型储能技术特点的认知。
考虑火-储联合调频(火电机组-混合储能)的协同控制策略(Matlab代码实现)
内容概要:本文围绕“考虑火-储联合调频(火电机组-混合储能)的协同控制策略”展开研究,提出一种基于Matlab仿真的协同控制方法,旨在提升电力系统频率调节的快速性与稳定性。通过构建火电机组与混合储能(如蓄电池、飞轮等)的联合调频模型,设计合理的功率分配机制与控制策略,充分发挥火电的持续调节能力与储能的快速响应优势,有效应对电网负荷波动与频率偏差。文中结合改进信号分解算法(如ICEEMDAN)与优化算法(如GWO),实现对调频信号的精准分频与储能单元的优化调度,提高系统整体调频效率与经济性。; 适合人群:具备一定电力系统基础知识和Matlab编程能力,从事新能源并网、电力系统稳定控制、储能技术应用等相关领域的研究生、科研人员及工程技术人员。; 使用场景及目标:①用于研究火电机组与混合储能在电网一次调频、二次调频中的协同作用机制;②为实际电力系统中储能配置与调频控制策略设计提供仿真验证平台与理论支持;③支撑相关课题研究、学术论文撰写及工程项目前期论证。; 阅读建议:建议结合Matlab代码深入理解控制算法实现细节,重点关注功率分配逻辑、信号分解过程与优化算法参数设置,并可通过修改系统参数进行对比仿真,以加深对协同控制效果的认识。
易语言源码SAVEPIC
易语言源码SAVEPIC
Hadoop生态社区
20,842
社区成员
4,695
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

