22,297
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享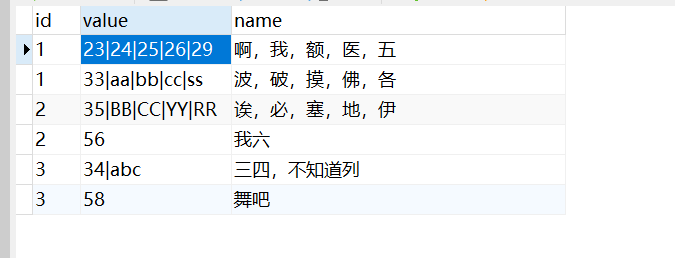

WITH testdata(id,value,[name]) AS (
SELECT 1,'23|24|25|26|29',N'啊,我,额,医,五' UNION ALL
SELECT 1,'33|aa|bb|cc|ss',N'波,破,摸,佛,各' UNION ALL
SELECT 2,'35|BB|CC|YY|RR',N'诶,必,塞,地,伊' UNION ALL
SELECT 2,'56',N'我六' UNION ALL
SELECT 3,'34|ab',N'三四,不知道咧' UNION ALL
SELECT 3,'58',N'舞吧'
)
SELECT id,t.value,t.name,v,n FROM testdata AS t
CROSS APPLY(VALUES(CONVERT(XML,'<n>'+REPLACE(t.value,'|','</n><n>')+'</n>'),(CONVERT(XML,'<n>'+REPLACE(t.[name],',','</n><n>')+'</n>')))) c(x1,x2)
OUTER APPLY(SELECT ROW_NUMBER()OVER(ORDER BY GETDATE()) AS rn,x.n.value('.','varchar(100)') AS v FROM c.x1.nodes('n')x(n)) vs
OUTER APPLY(SELECT ROW_NUMBER()OVER(ORDER BY GETDATE()) AS rn,x.n.value('.','nvarchar(100)') AS n FROM c.x2.nodes('n')x(n)) ns
WHERE vs.rn=ns.rn
+----+----------------+-----------+----+------+
| id | value | name | v | n |
+----+----------------+-----------+----+------+
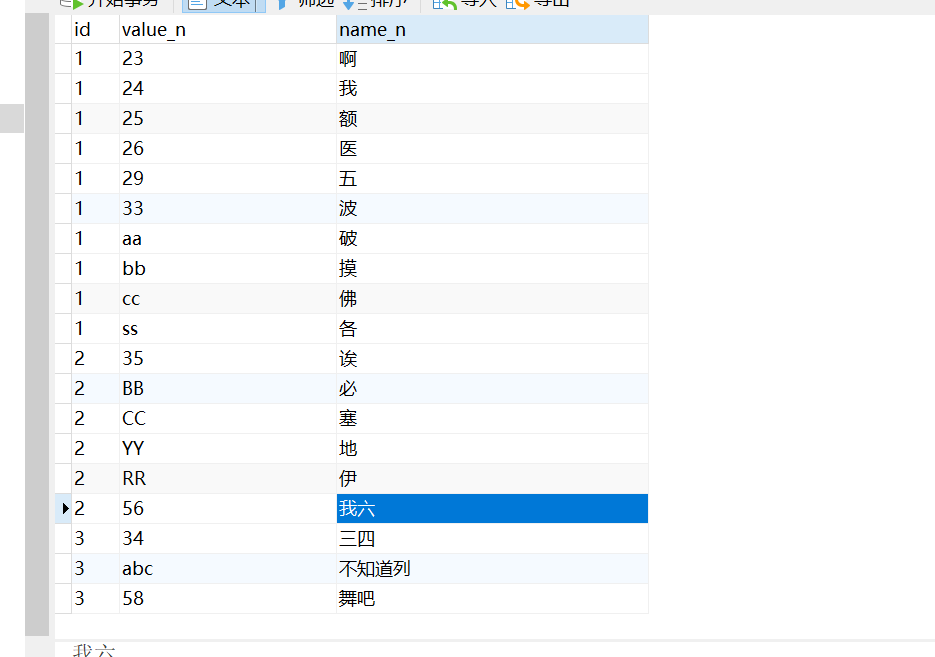
| 1 | 23|24|25|26|29 | 啊,我,额,医,五 | 23 | 啊 |
| 1 | 23|24|25|26|29 | 啊,我,额,医,五 | 24 | 我 |
| 1 | 23|24|25|26|29 | 啊,我,额,医,五 | 25 | 额 |
| 1 | 23|24|25|26|29 | 啊,我,额,医,五 | 26 | 医 |
| 1 | 23|24|25|26|29 | 啊,我,额,医,五 | 29 | 五 |
| 2 | 35|BB|CC|YY|RR | 诶,必,塞,地,伊 | 35 | 诶 |
| 2 | 35|BB|CC|YY|RR | 诶,必,塞,地,伊 | BB | 必 |
| 2 | 35|BB|CC|YY|RR | 诶,必,塞,地,伊 | CC | 塞 |
| 2 | 35|BB|CC|YY|RR | 诶,必,塞,地,伊 | YY | 地 |
| 2 | 35|BB|CC|YY|RR | 诶,必,塞,地,伊 | RR | 伊 |
| 2 | 56 | 我六 | 56 | 我六 |
| 3 | 34|ab | 三四,不知道咧 | 34 | 三四 |
| 3 | 34|ab | 三四,不知道咧 | ab | 不知道咧 |
| 3 | 58 | 舞吧 | 58 | 舞吧 |
| 1 | 33|aa|bb|cc|ss | 波,破,摸,佛,各 | 33 | 波 |
| 1 | 33|aa|bb|cc|ss | 波,破,摸,佛,各 | aa | 破 |
| 1 | 33|aa|bb|cc|ss | 波,破,摸,佛,各 | bb | 摸 |
| 1 | 33|aa|bb|cc|ss | 波,破,摸,佛,各 | cc | 佛 |
| 1 | 33|aa|bb|cc|ss | 波,破,摸,佛,各 | ss | 各 |
+----+----------------+-----------+----+------+


IF OBJECT_ID('value_mid') IS NOT NULL DROP TABLE value_mid
CREATE TABLE value_mid (
mid INT IDENTITY(1,1),
id INT NOT NULL,
[value] NVARCHAR(20) NOT NULL,
CONSTRAINT PK_value_mid PRIMARY KEY NONCLUSTERED(
mid
)
)
CREATE CLUSTERED INDEX IX_value_mid_id_vlue ON value_mid(id,[value])
IF OBJECT_ID('name_mid') IS NOT NULL DROP TABLE name_mid
CREATE TABLE name_mid (
mid INT IDENTITY(1,1),
id INT NOT NULL,
[name] NVARCHAR(20) NOT NULL,
CONSTRAINT PK_name_mid PRIMARY KEY NONCLUSTERED(
mid
)
)
CREATE CLUSTERED INDEX IX_name_mid_id_vlue ON name_mid(id,[name])

WITH TABLE_SEQ
AS
(SELECT 0 AS NUMBER
UNION ALL
SELECT NUMBER+1 FROM TABLE_SEQ
WHERE NUMBER+1<=2000),
CTE
AS
(SELECT *,ROW_NUMBER() OVER (PARTITION BY ID ORDER BY (SELECT 1)) AS SEQ_1
FROM TABLE)
SELECT A.ID,A.single_VALUE AS VALUE_N,B.single_NAME AS NAME_N
FROM
(SELECT A.ID,SEQ_1,
SUBSTRING(VALUE_N,B.NUMBER,CHARINDEX('|',VALUE_N+'|',B.NUMBER)-B.NUMBER) AS single_VALUE,
ROW_NUMBER() OVER (PARTITION BY ID,SEQ_1 ORDER BY NUMBER) AS SEQ_2
FROM CTE A
JOIN TABLE_SEQ AS B ON CHARINDEX('|','|'+A.VALUE_N,B.number)=B.number ) AS A
JOIN
(SELECT A.ID,SEQ_1,
SUBSTRING(NAME_N,B.NUMBER,CHARINDEX(',',NAME_N+',',B.NUMBER)-B.NUMBER) AS single_NAME,
ROW_NUMBER() OVER (PARTITION BY ID,SEQ_1 ORDER BY NUMBER) AS SEQ_2
FROM CTE A
JOIN TABLE_SEQ AS B ON CHARINDEX(',',','+A.NAME_N,B.number)=B.number ) AS B
ON A.ID=B.ID AND A.SEQ_1=B.SEQ_1 AND A.SEQ_2=B.SEQ_2
ORDER BY A.ID,A.SEQ_1,B.SEQ_2
OPTION(MAXRECURSION 0)

CREATE FUNCTION [dbo].[ufn_SplitStringToTable]
(
@str VARCHAR(MAX) ,
@split VARCHAR(10)
)
RETURNS TABLE
AS
RETURN
( SELECT B.id
FROM ( SELECT [value] = CONVERT(XML , '<v>' + REPLACE(@str , @split , '</v><v>')
+ '</v>')
) A
OUTER APPLY ( SELECT id = N.v.value('.' , 'varchar(100)')
FROM A.[value].nodes('/v') N ( v )
) B
)
--测试数据
IF OBJECT_ID('tempdb..#tab') IS NOT NULL
DROP TABLE #tab
CREATE TABLE #tab(
id INT,
VALUE VARCHAR(20),
NAME VARCHAR(20)
)
INSERT INTO #tab
SELECT 1,'12|23','你好,hello' union all
SELECT 1,'456|1|35','Abc,efc,kkk' UNION ALL
SELECT 2,'12','pppp'
--测试数据结束
IF OBJECT_ID('tempdb..#t') IS NOT NULL
DROP TABLE #t
SELECT a.id AS id_mstr,a.[VALUE],a.name,b.*,identity (int,1,1) as rn into #t FROM #tab a
OUTER APPLY dbo.ufn_SplitStringToTable(a.[VALUE],'|') b
IF OBJECT_ID('tempdb..#t2') IS NOT NULL
DROP TABLE #t2
SELECT a.id AS id_mstr,a.[VALUE],a.name,b.*,identity (int,1,1) as rn into #t2 FROM #tab a
OUTER APPLY dbo.ufn_SplitStringToTable(a.name,',') b
SELECT a.id_mstr,
a.value,
a.name,
a.id AS value_n,
b.id AS name_n
FROM #t a
INNER JOIN #t2 b
ON a.rn = b.rn
AND a.id_mstr = b.id_mstr
AND a.value = b.value