社区
脚本语言
帖子详情
Python sklearn 随机森林
yuer593746122
2017-11-08 03:45:50
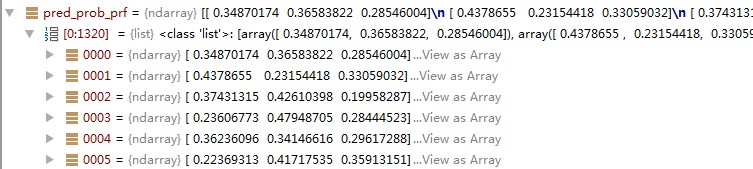
RandomForestClassifier 中怎么知道每棵树对 类别的投票百分比呀,难道RandomForestClassifier的结果是直接进行的平均投票吗?
...全文
537
2
打赏
收藏
Python sklearn 随机森林
RandomForestClassifier 中怎么知道每棵树对 类别的投票百分比呀,难道RandomForestClassifier的结果是直接进行的平均投票吗?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
yuer593746122
2017-11-08
打赏
举报
回复
随机森林中最后的结果,不是直接求平均,怎样用加权平均的方法获得结果呢?
随机森林
模型
sklearn
_使用
python
+
sklearn
实现
随机森林
的特征重要性
本文通过一个示例展示了如何使用
Python
的
sklearn
库实现
随机森林
模型,并评估特征的重要性和在树间的差异性。结果显示,三个特征对于分类任务具有显著信息价值,而其他特征则不重要。
python
随机森林
_使用
python
+
sklearn
实现
随机森林
的特征重要性
该博客通过一个示例展示了如何利用
Python
和
sklearn
库实现
随机森林
,并评估特征在分类任务中的重要性。结果显示,
随机森林
确认了3个特征具有显著信息,而其他特征则不重要。同时,文章邀请读者加入相关学习交流群深入学习scikit-learn。
Python
机器学习之
sklearn
随机森林
本文介绍了
随机森林
这一集成学习工具的基本概念,并通过一个实际案例展示了如何使用
Python
的
sklearn
库进行
随机森林
模型的参数调优,以提高预测准确性。
python
随机森林
_使用
python
+
sklearn
实现
随机森林
的OOB错误
本文详细介绍了如何使用
Python
的
sklearn
库来实现
随机森林
,并重点讲解了
随机森林
中的Out-of-Bag(OOB)误差的计算和应用,通过实例代码展示了
随机森林
模型的构建与OOB误差的获取过程。
基于
python
sklearn
的 RandomForest
随机森林
类实现
本文详细介绍如何使用
Python
的
sklearn
库实现
随机森林
算法,包括数据预处理、模型训练、性能评估与调优,以及混淆矩阵可视化。通过调整决策树数量和深度,找到最佳模型参数,提高预测准确性。
脚本语言
37,738
社区成员
34,210
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


