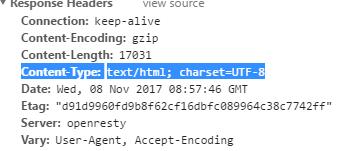
代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib,urllib2
import sys
page = 1
url = 'http://www.qiushibaike.com/hot/page/1' + str(page)
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'AlexaToolbar-ALX_NS_PH':'AlexaToolbar/alx-4.0',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'_xsrf=2|242ca447|bd506c7f8bc26e48eae656ed4c19d099|1510131460',
'Host':'www.qiushibaike.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
}
try:
request = urllib2.Request(url,headers = headers)
reponse = urllib2.urlopen(request)
c = reponse.read()
print c
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
运行后爬了一堆乱码,改为c = reponse.read().decode('utf-8')后报错,如下:
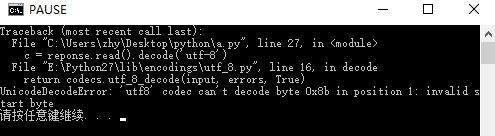
网上找了很多帖子也不知道怎么解决


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

 多谢多谢
多谢多谢