62,272
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
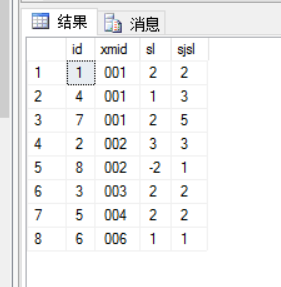
ID xmid sl ljsl
1 001 2 2
2 002 3 3
3 003 2 2
4 001 1 3
5 004 2 2
6 006 1 1
7 001 2 5
8 002 -2 1



SELECT a.*,b.ljsl FROM TJ a JOIN
(SELECT t1.ID,SUM(t2.sl) ljsl
FROM TJ t1
LEFT JOIN TJ t2
ON t1.xmid=t2.xmid AND t1.ID >= t2.ID GROUP BY t1.ID) AS b ON a.ID=b.ID



use Tempdb
go
--> --> 听雨停了-->测试数据
if not object_id(N'Tempdb..#tab') is null
drop table #tab
Go
Create table #tab([ID] int,[xmid] nvarchar(23),[sl] int)
Insert #tab
select 1,N'001',2 union all
select 2,N'002',3 union all
select 3,N'003',2 union all
select 4,N'001',1 union all
select 5,N'004',2 union all
select 6,N'006',1 union all
select 7,N'001',2 union all
select 8,N'002',-2
--测试数据结束
;WITH cte AS (
SELECT * ,row_number() over(PARTITION BY xmid ORDER BY id ) as rn FROM #tab
),
cte2 AS (
SELECT id,xmid,sl,rn,sl AS sjsl FROM cte WHERE rn=1
UNION ALL
SELECT a.id,a.xmid,a.sl,a.rn,a.sl+b.sjsl FROM cte a
INNER JOIN cte2 b ON a.xmid=b.xmid AND a.rn=b.rn+1
)
SELECT id,xmid,sl,sjsl
FROM cte2
ORDER BY xmid,rn