

20,845
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 这是官网上的一张图,官网带的解释如下:
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
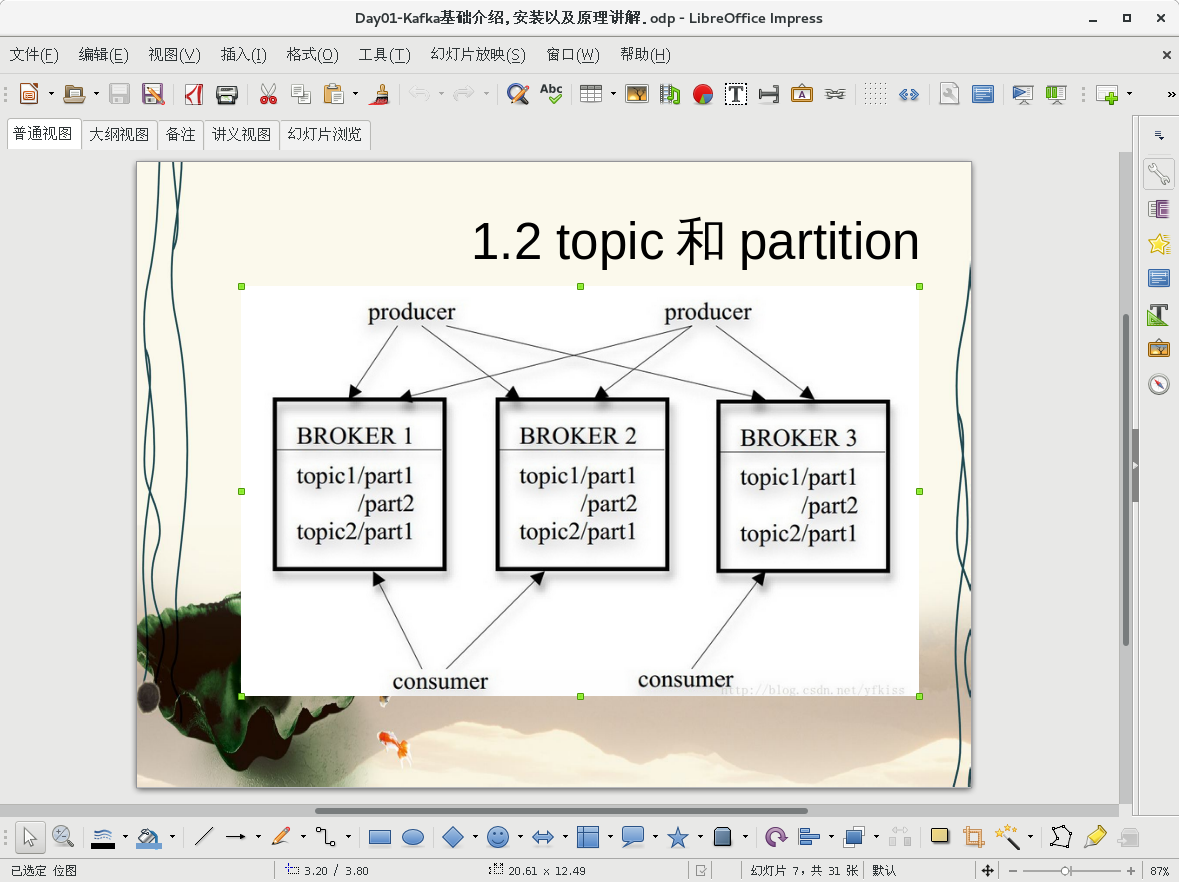
意思是:日志的分区partition (分布)在Kafka集群不同的服务器上,每一台服务器处理数据和请求的时候,共享这些分区。每一个分区都会配置服务器备份数量,保证容错.
如果有搞不清楚的地方或者网上说法不一致的,去官网看,官网是最权威的解释,如果官网的英文看不懂,可以看ApacheCN,有团队在翻译官网,但是翻译总是会有作者主观理解,个人还是建议看英文官网[/quote]
sorry,可能官网的英文粘错了,应该是这句The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance. 上面那句是解释那个图消费者组的相关问题的。现在贴的这句是关于图中topic和分区关系的。可以参看一篇博客来理解,kafka分区原理图 http://blog.csdn.net/liuwei063608/article/details/46378863
这是官网上的一张图,官网带的解释如下:
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
意思是:日志的分区partition (分布)在Kafka集群不同的服务器上,每一台服务器处理数据和请求的时候,共享这些分区。每一个分区都会配置服务器备份数量,保证容错.
如果有搞不清楚的地方或者网上说法不一致的,去官网看,官网是最权威的解释,如果官网的英文看不懂,可以看ApacheCN,有团队在翻译官网,但是翻译总是会有作者主观理解,个人还是建议看英文官网[/quote]
sorry,可能官网的英文粘错了,应该是这句The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance. 上面那句是解释那个图消费者组的相关问题的。现在贴的这句是关于图中topic和分区关系的。可以参看一篇博客来理解,kafka分区原理图 http://blog.csdn.net/liuwei063608/article/details/46378863


