3,491
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
create table dba_object_testIndex as select * from dba_objects t ;
update dba_object_testIndex t set t.object_id = 40000 where t.object_id > 40000 ;
dba_object_testIndexSELECT * FROM dba_object_testIndex T WHERE T.OBJECT_ID = 1000SELECT * FROM dba_object_testIndex T WHERE T.OBJECT_ID = 40000


 另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
[/quote]
“有直方图不安全”这种说法,说反了,有直方图应该更安全,但是,直方图也不是万能的。
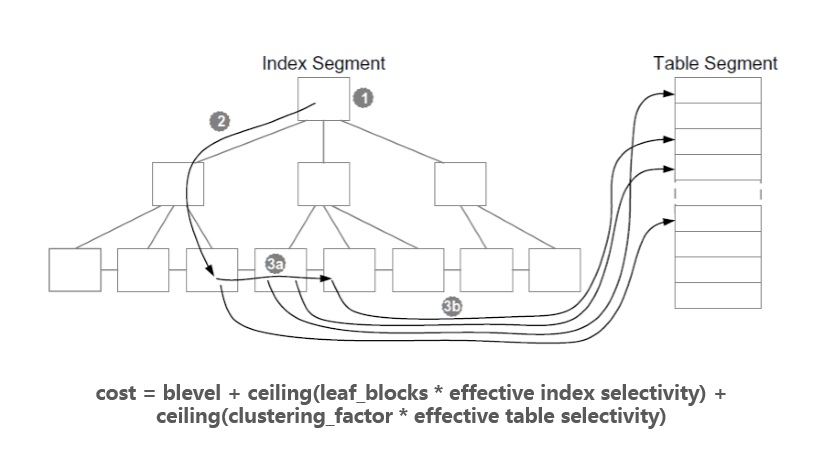
直方图一定程度上可以反映某个字段的数据分布情况,非索引字段也可以收集,具体如何收集直方图,可参考Oracle在线文档中dbms_stats包中的method_opt参数。最常用的就是for all indexed columns,也就是说在索引字段上收集直方图,为什么常用呢?因为对于单表访问来讲,正常情况下,只有表扫描和索引扫描两种途径,而什么时候要用索引扫描,什么时候用表扫描就是上面那个公式来决定的,其中的选择率就与直方图相关:
1、前面已经提到:直方图一定程度上反映了数据分布情况,比如某个id字段,是表中主键,这意味着他是均匀分布的,而且每个ID取值只可能返回一条记录,从直方图上,至少可以得到“均匀分布”这个信息,而且如果我们的sql条件中有这个ID字段,那么CBO会走主键索引扫描(index unique scan),这个执行计划是相当高效的;
2、但如果某个字段是类型之类的字段呢?比如一个IT公司内部的岗位类型TYPE:有开发,有测试,有项目经理,有总经理,有销售等等,开发可能是最多的,占了50%,测试20%,项目经理5%,销售5%,总经理1%,其他20%,如果这样的字段上没有直方图,CBO也会认为这个字段是均衡分布的,也就是说,每个岗位的占比都会是100/6*100%,差不多16.67%,这可能会发生什么问题?如果我们选择TYPE='开发',原本因为50%的选择率,索引扫描的cost会很高,一般来说,这么大的占比,索引扫描的cost会高过全表扫描的cost,那么这时候CBO会选择全表扫描,而不是索引扫描来完成这个SQL,但是有了这个错误的选择率16.67%,CBO极有可能还是选择索引扫描,绝大部分情况下,选择率超过50%的SQL,考虑到数据很多,返表也会很费劲,走索引扫描肯定是更坑的路径,那怎么办?直方图能解决一部分类似的烦恼:简单说,Oracle会根据TYPE字段的取值,将数据划分为6部分,放到不同的“桶”中(这个桶就是method_opt参数中size指定的大小),每个桶放TYPE取值相同的数据,那么每个桶中某个取值数据量是多少,占整表比例是多少就很清楚了,TYPE='开发',CBO能根据直方图明确地判断出50%的选择率,最终极有可能使用全表扫描来完成这次查询,而若是TYPE='总经理',CBO也能知道我这次要查询表中1%数据的信息,cost会相当低,比全表扫描后过滤数据低得多的多,自然会选择索引扫描完成本次查询;
3、以上其实还有个问题:因为直方图划分数据时候的桶数是有上限的,尤其在12c之前,最大桶数如果我没记错应该是254,你可以看到如果某列数据的唯一值超过这个的时候会发生什么事情:很多取值并不一样的数据会被丢到同一个桶中,这样数据分布情况的判断随着字段唯一值的增大,会变得越来越不靠谱,但无论怎样,都比没有直方图情况下,单纯地认为“数据是均匀分布的”要好的多,所以说,直方图让CBO选择执行计划更安全,但它也不是万能的,有它的缺陷;
4、你说的硬解析的问题,其实也许不是问题,或者糟糕的情况下,也有可能带来更多的麻烦,因为这种情况下你可能会使用绑定变量,当然在使用绑定变量的情况下,如果实际数据分布相当不均匀,事情变得更加复杂,你可能要考虑绑定变量比较特别的选择率计算、考虑Oracle为了解决绑定变量问题引入的一些特性:比如绑定变量窥测、自动游标调整、基数反馈等等,用你的话来说,这些很多时候也会让执行计划便得“不安全”,而且实际工作中,恐怕你会发现他们带来的问题会比直方图要多的多,直方图只是统计信息的一种,和其他统计信息一样,他只能从整体上让数据库中的SQL往好的方向发展,但它不能保证100%的SQL全部得到更好的性能,另外,我们现在讨论的还只是等值单表查询,这是最最简单的情况,即便如此,cost计算公式还是有懈可击的,如果涉及到更复杂的单表查询,甚至是多表join,cost的计算公式会更加的“不靠谱”——虽然说Oracle的CBO在RDBMS中首屈一指,但不得不承认,还是不够智能,也许智能是一个可以无限接近,但永远无法达到的目标;
5、上面第1点和第2点举了两个简单的例子来说明直方图的功用,实际上可能除了等值查询,还有范围查询,开区间,闭区间,这些情况也会使选择率的计算变得更复杂,如果考虑第4点提到的绑定变量,那可能就更刺激了。讲那么多,没有去定量的说明CBO的cost是怎么计算的,如果你有兴趣,可以参考jonathan lewis的《cost-based oracle fundamentals》(实现说明,中文版翻译的有点坑
另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
[/quote]
“有直方图不安全”这种说法,说反了,有直方图应该更安全,但是,直方图也不是万能的。
直方图一定程度上可以反映某个字段的数据分布情况,非索引字段也可以收集,具体如何收集直方图,可参考Oracle在线文档中dbms_stats包中的method_opt参数。最常用的就是for all indexed columns,也就是说在索引字段上收集直方图,为什么常用呢?因为对于单表访问来讲,正常情况下,只有表扫描和索引扫描两种途径,而什么时候要用索引扫描,什么时候用表扫描就是上面那个公式来决定的,其中的选择率就与直方图相关:
1、前面已经提到:直方图一定程度上反映了数据分布情况,比如某个id字段,是表中主键,这意味着他是均匀分布的,而且每个ID取值只可能返回一条记录,从直方图上,至少可以得到“均匀分布”这个信息,而且如果我们的sql条件中有这个ID字段,那么CBO会走主键索引扫描(index unique scan),这个执行计划是相当高效的;
2、但如果某个字段是类型之类的字段呢?比如一个IT公司内部的岗位类型TYPE:有开发,有测试,有项目经理,有总经理,有销售等等,开发可能是最多的,占了50%,测试20%,项目经理5%,销售5%,总经理1%,其他20%,如果这样的字段上没有直方图,CBO也会认为这个字段是均衡分布的,也就是说,每个岗位的占比都会是100/6*100%,差不多16.67%,这可能会发生什么问题?如果我们选择TYPE='开发',原本因为50%的选择率,索引扫描的cost会很高,一般来说,这么大的占比,索引扫描的cost会高过全表扫描的cost,那么这时候CBO会选择全表扫描,而不是索引扫描来完成这个SQL,但是有了这个错误的选择率16.67%,CBO极有可能还是选择索引扫描,绝大部分情况下,选择率超过50%的SQL,考虑到数据很多,返表也会很费劲,走索引扫描肯定是更坑的路径,那怎么办?直方图能解决一部分类似的烦恼:简单说,Oracle会根据TYPE字段的取值,将数据划分为6部分,放到不同的“桶”中(这个桶就是method_opt参数中size指定的大小),每个桶放TYPE取值相同的数据,那么每个桶中某个取值数据量是多少,占整表比例是多少就很清楚了,TYPE='开发',CBO能根据直方图明确地判断出50%的选择率,最终极有可能使用全表扫描来完成这次查询,而若是TYPE='总经理',CBO也能知道我这次要查询表中1%数据的信息,cost会相当低,比全表扫描后过滤数据低得多的多,自然会选择索引扫描完成本次查询;
3、以上其实还有个问题:因为直方图划分数据时候的桶数是有上限的,尤其在12c之前,最大桶数如果我没记错应该是254,你可以看到如果某列数据的唯一值超过这个的时候会发生什么事情:很多取值并不一样的数据会被丢到同一个桶中,这样数据分布情况的判断随着字段唯一值的增大,会变得越来越不靠谱,但无论怎样,都比没有直方图情况下,单纯地认为“数据是均匀分布的”要好的多,所以说,直方图让CBO选择执行计划更安全,但它也不是万能的,有它的缺陷;
4、你说的硬解析的问题,其实也许不是问题,或者糟糕的情况下,也有可能带来更多的麻烦,因为这种情况下你可能会使用绑定变量,当然在使用绑定变量的情况下,如果实际数据分布相当不均匀,事情变得更加复杂,你可能要考虑绑定变量比较特别的选择率计算、考虑Oracle为了解决绑定变量问题引入的一些特性:比如绑定变量窥测、自动游标调整、基数反馈等等,用你的话来说,这些很多时候也会让执行计划便得“不安全”,而且实际工作中,恐怕你会发现他们带来的问题会比直方图要多的多,直方图只是统计信息的一种,和其他统计信息一样,他只能从整体上让数据库中的SQL往好的方向发展,但它不能保证100%的SQL全部得到更好的性能,另外,我们现在讨论的还只是等值单表查询,这是最最简单的情况,即便如此,cost计算公式还是有懈可击的,如果涉及到更复杂的单表查询,甚至是多表join,cost的计算公式会更加的“不靠谱”——虽然说Oracle的CBO在RDBMS中首屈一指,但不得不承认,还是不够智能,也许智能是一个可以无限接近,但永远无法达到的目标;
5、上面第1点和第2点举了两个简单的例子来说明直方图的功用,实际上可能除了等值查询,还有范围查询,开区间,闭区间,这些情况也会使选择率的计算变得更复杂,如果考虑第4点提到的绑定变量,那可能就更刺激了。讲那么多,没有去定量的说明CBO的cost是怎么计算的,如果你有兴趣,可以参考jonathan lewis的《cost-based oracle fundamentals》(实现说明,中文版翻译的有点坑 ),但在实际工作中,我觉得了解一些定性的东西就够了,足够你去优化95%以上的SQL。[/quote]
简直膜拜大佬的回答啊~ 对直方图和执行计划竟然理解得这么深。。基本上算是解决了我的疑惑,一个小小的问题引起了你这么多的回复,感谢感谢~
),但在实际工作中,我觉得了解一些定性的东西就够了,足够你去优化95%以上的SQL。[/quote]
简直膜拜大佬的回答啊~ 对直方图和执行计划竟然理解得这么深。。基本上算是解决了我的疑惑,一个小小的问题引起了你这么多的回复,感谢感谢~ 另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
[/quote]
“有直方图不安全”这种说法,说反了,有直方图应该更安全,但是,直方图也不是万能的。
直方图一定程度上可以反映某个字段的数据分布情况,非索引字段也可以收集,具体如何收集直方图,可参考Oracle在线文档中dbms_stats包中的method_opt参数。最常用的就是for all indexed columns,也就是说在索引字段上收集直方图,为什么常用呢?因为对于单表访问来讲,正常情况下,只有表扫描和索引扫描两种途径,而什么时候要用索引扫描,什么时候用表扫描就是上面那个公式来决定的,其中的选择率就与直方图相关:
1、前面已经提到:直方图一定程度上反映了数据分布情况,比如某个id字段,是表中主键,这意味着他是均匀分布的,而且每个ID取值只可能返回一条记录,从直方图上,至少可以得到“均匀分布”这个信息,而且如果我们的sql条件中有这个ID字段,那么CBO会走主键索引扫描(index unique scan),这个执行计划是相当高效的;
2、但如果某个字段是类型之类的字段呢?比如一个IT公司内部的岗位类型TYPE:有开发,有测试,有项目经理,有总经理,有销售等等,开发可能是最多的,占了50%,测试20%,项目经理5%,销售5%,总经理1%,其他20%,如果这样的字段上没有直方图,CBO也会认为这个字段是均衡分布的,也就是说,每个岗位的占比都会是100/6*100%,差不多16.67%,这可能会发生什么问题?如果我们选择TYPE='开发',原本因为50%的选择率,索引扫描的cost会很高,一般来说,这么大的占比,索引扫描的cost会高过全表扫描的cost,那么这时候CBO会选择全表扫描,而不是索引扫描来完成这个SQL,但是有了这个错误的选择率16.67%,CBO极有可能还是选择索引扫描,绝大部分情况下,选择率超过50%的SQL,考虑到数据很多,返表也会很费劲,走索引扫描肯定是更坑的路径,那怎么办?直方图能解决一部分类似的烦恼:简单说,Oracle会根据TYPE字段的取值,将数据划分为6部分,放到不同的“桶”中(这个桶就是method_opt参数中size指定的大小),每个桶放TYPE取值相同的数据,那么每个桶中某个取值数据量是多少,占整表比例是多少就很清楚了,TYPE='开发',CBO能根据直方图明确地判断出50%的选择率,最终极有可能使用全表扫描来完成这次查询,而若是TYPE='总经理',CBO也能知道我这次要查询表中1%数据的信息,cost会相当低,比全表扫描后过滤数据低得多的多,自然会选择索引扫描完成本次查询;
3、以上其实还有个问题:因为直方图划分数据时候的桶数是有上限的,尤其在12c之前,最大桶数如果我没记错应该是254,你可以看到如果某列数据的唯一值超过这个的时候会发生什么事情:很多取值并不一样的数据会被丢到同一个桶中,这样数据分布情况的判断随着字段唯一值的增大,会变得越来越不靠谱,但无论怎样,都比没有直方图情况下,单纯地认为“数据是均匀分布的”要好的多,所以说,直方图让CBO选择执行计划更安全,但它也不是万能的,有它的缺陷;
4、你说的硬解析的问题,其实也许不是问题,或者糟糕的情况下,也有可能带来更多的麻烦,因为这种情况下你可能会使用绑定变量,当然在使用绑定变量的情况下,如果实际数据分布相当不均匀,事情变得更加复杂,你可能要考虑绑定变量比较特别的选择率计算、考虑Oracle为了解决绑定变量问题引入的一些特性:比如绑定变量窥测、自动游标调整、基数反馈等等,用你的话来说,这些很多时候也会让执行计划便得“不安全”,而且实际工作中,恐怕你会发现他们带来的问题会比直方图要多的多,直方图只是统计信息的一种,和其他统计信息一样,他只能从整体上让数据库中的SQL往好的方向发展,但它不能保证100%的SQL全部得到更好的性能,另外,我们现在讨论的还只是等值单表查询,这是最最简单的情况,即便如此,cost计算公式还是有懈可击的,如果涉及到更复杂的单表查询,甚至是多表join,cost的计算公式会更加的“不靠谱”——虽然说Oracle的CBO在RDBMS中首屈一指,但不得不承认,还是不够智能,也许智能是一个可以无限接近,但永远无法达到的目标;
5、上面第1点和第2点举了两个简单的例子来说明直方图的功用,实际上可能除了等值查询,还有范围查询,开区间,闭区间,这些情况也会使选择率的计算变得更复杂,如果考虑第4点提到的绑定变量,那可能就更刺激了。讲那么多,没有去定量的说明CBO的cost是怎么计算的,如果你有兴趣,可以参考jonathan lewis的《cost-based oracle fundamentals》(实现说明,中文版翻译的有点坑),但在实际工作中,我觉得了解一些定性的东西就够了,足够你去优化95%以上的SQL。
另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
[/quote]
“有直方图不安全”这种说法,说反了,有直方图应该更安全,但是,直方图也不是万能的。
直方图一定程度上可以反映某个字段的数据分布情况,非索引字段也可以收集,具体如何收集直方图,可参考Oracle在线文档中dbms_stats包中的method_opt参数。最常用的就是for all indexed columns,也就是说在索引字段上收集直方图,为什么常用呢?因为对于单表访问来讲,正常情况下,只有表扫描和索引扫描两种途径,而什么时候要用索引扫描,什么时候用表扫描就是上面那个公式来决定的,其中的选择率就与直方图相关:
1、前面已经提到:直方图一定程度上反映了数据分布情况,比如某个id字段,是表中主键,这意味着他是均匀分布的,而且每个ID取值只可能返回一条记录,从直方图上,至少可以得到“均匀分布”这个信息,而且如果我们的sql条件中有这个ID字段,那么CBO会走主键索引扫描(index unique scan),这个执行计划是相当高效的;
2、但如果某个字段是类型之类的字段呢?比如一个IT公司内部的岗位类型TYPE:有开发,有测试,有项目经理,有总经理,有销售等等,开发可能是最多的,占了50%,测试20%,项目经理5%,销售5%,总经理1%,其他20%,如果这样的字段上没有直方图,CBO也会认为这个字段是均衡分布的,也就是说,每个岗位的占比都会是100/6*100%,差不多16.67%,这可能会发生什么问题?如果我们选择TYPE='开发',原本因为50%的选择率,索引扫描的cost会很高,一般来说,这么大的占比,索引扫描的cost会高过全表扫描的cost,那么这时候CBO会选择全表扫描,而不是索引扫描来完成这个SQL,但是有了这个错误的选择率16.67%,CBO极有可能还是选择索引扫描,绝大部分情况下,选择率超过50%的SQL,考虑到数据很多,返表也会很费劲,走索引扫描肯定是更坑的路径,那怎么办?直方图能解决一部分类似的烦恼:简单说,Oracle会根据TYPE字段的取值,将数据划分为6部分,放到不同的“桶”中(这个桶就是method_opt参数中size指定的大小),每个桶放TYPE取值相同的数据,那么每个桶中某个取值数据量是多少,占整表比例是多少就很清楚了,TYPE='开发',CBO能根据直方图明确地判断出50%的选择率,最终极有可能使用全表扫描来完成这次查询,而若是TYPE='总经理',CBO也能知道我这次要查询表中1%数据的信息,cost会相当低,比全表扫描后过滤数据低得多的多,自然会选择索引扫描完成本次查询;
3、以上其实还有个问题:因为直方图划分数据时候的桶数是有上限的,尤其在12c之前,最大桶数如果我没记错应该是254,你可以看到如果某列数据的唯一值超过这个的时候会发生什么事情:很多取值并不一样的数据会被丢到同一个桶中,这样数据分布情况的判断随着字段唯一值的增大,会变得越来越不靠谱,但无论怎样,都比没有直方图情况下,单纯地认为“数据是均匀分布的”要好的多,所以说,直方图让CBO选择执行计划更安全,但它也不是万能的,有它的缺陷;
4、你说的硬解析的问题,其实也许不是问题,或者糟糕的情况下,也有可能带来更多的麻烦,因为这种情况下你可能会使用绑定变量,当然在使用绑定变量的情况下,如果实际数据分布相当不均匀,事情变得更加复杂,你可能要考虑绑定变量比较特别的选择率计算、考虑Oracle为了解决绑定变量问题引入的一些特性:比如绑定变量窥测、自动游标调整、基数反馈等等,用你的话来说,这些很多时候也会让执行计划便得“不安全”,而且实际工作中,恐怕你会发现他们带来的问题会比直方图要多的多,直方图只是统计信息的一种,和其他统计信息一样,他只能从整体上让数据库中的SQL往好的方向发展,但它不能保证100%的SQL全部得到更好的性能,另外,我们现在讨论的还只是等值单表查询,这是最最简单的情况,即便如此,cost计算公式还是有懈可击的,如果涉及到更复杂的单表查询,甚至是多表join,cost的计算公式会更加的“不靠谱”——虽然说Oracle的CBO在RDBMS中首屈一指,但不得不承认,还是不够智能,也许智能是一个可以无限接近,但永远无法达到的目标;
5、上面第1点和第2点举了两个简单的例子来说明直方图的功用,实际上可能除了等值查询,还有范围查询,开区间,闭区间,这些情况也会使选择率的计算变得更复杂,如果考虑第4点提到的绑定变量,那可能就更刺激了。讲那么多,没有去定量的说明CBO的cost是怎么计算的,如果你有兴趣,可以参考jonathan lewis的《cost-based oracle fundamentals》(实现说明,中文版翻译的有点坑),但在实际工作中,我觉得了解一些定性的东西就够了,足够你去优化95%以上的SQL。
另外,我提的这个问题,翻了<基于Oracle的SQL优化>这本书,找到了类似的问题~ 我提的这个问题属于列数据分布不均衡,Oracle 对于分布不均衡的数据采用的是直方图来解决的。但是如果该列存在索引,Oracle又收集了该列的直方图统计信息,那么执行计划将变得不安全~ 即执行计划会根据谓词传入参数变化,Oracle虽然能够大概率选对最正确的执行计划,但是也导致了每次都可能发生硬解析~
 那就简单说下与索引相关的几个参数,包括4#楼提到的:optimizer_index_cost_adj:
optimizer_index_cost_adj:这个默认值是100,取值是1~10000,如果设置为非默认值,那么上面的索引扫描io cost公式还得乘上系数:optimizer_index_cost_adj/100;
optimizer_index_caching:会影响嵌套循环和in-list的索引扫描cost计算,意思嘛,就在caching这个词中了,默认为0,若非默认值,则上述公式的中间部分还要乘上系数:(1-optimizer_index_caching/100);
db_file_multiblock_read_count:影响全表扫描的io cost计算,反过来也就会影响CBO是否选择索引扫描,因为单表访问就这两种路径;
optimizer_mode:默认为all_rows,返回所有数据,这个会从较高层次影响优化器的选择,可以看到很多程序员迷信早期的一些“优化方案”,经常喜欢设置这个为first_rows,这会导致Oracle更倾向于生成类似分页查询的执行计划,在很多场景中实际效果相当的烂,烂,烂~~重要的事情说三遍啊说三遍。
那就简单说下与索引相关的几个参数,包括4#楼提到的:optimizer_index_cost_adj:
optimizer_index_cost_adj:这个默认值是100,取值是1~10000,如果设置为非默认值,那么上面的索引扫描io cost公式还得乘上系数:optimizer_index_cost_adj/100;
optimizer_index_caching:会影响嵌套循环和in-list的索引扫描cost计算,意思嘛,就在caching这个词中了,默认为0,若非默认值,则上述公式的中间部分还要乘上系数:(1-optimizer_index_caching/100);
db_file_multiblock_read_count:影响全表扫描的io cost计算,反过来也就会影响CBO是否选择索引扫描,因为单表访问就这两种路径;
optimizer_mode:默认为all_rows,返回所有数据,这个会从较高层次影响优化器的选择,可以看到很多程序员迷信早期的一些“优化方案”,经常喜欢设置这个为first_rows,这会导致Oracle更倾向于生成类似分页查询的执行计划,在很多场景中实际效果相当的烂,烂,烂~~重要的事情说三遍啊说三遍。