22,209
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

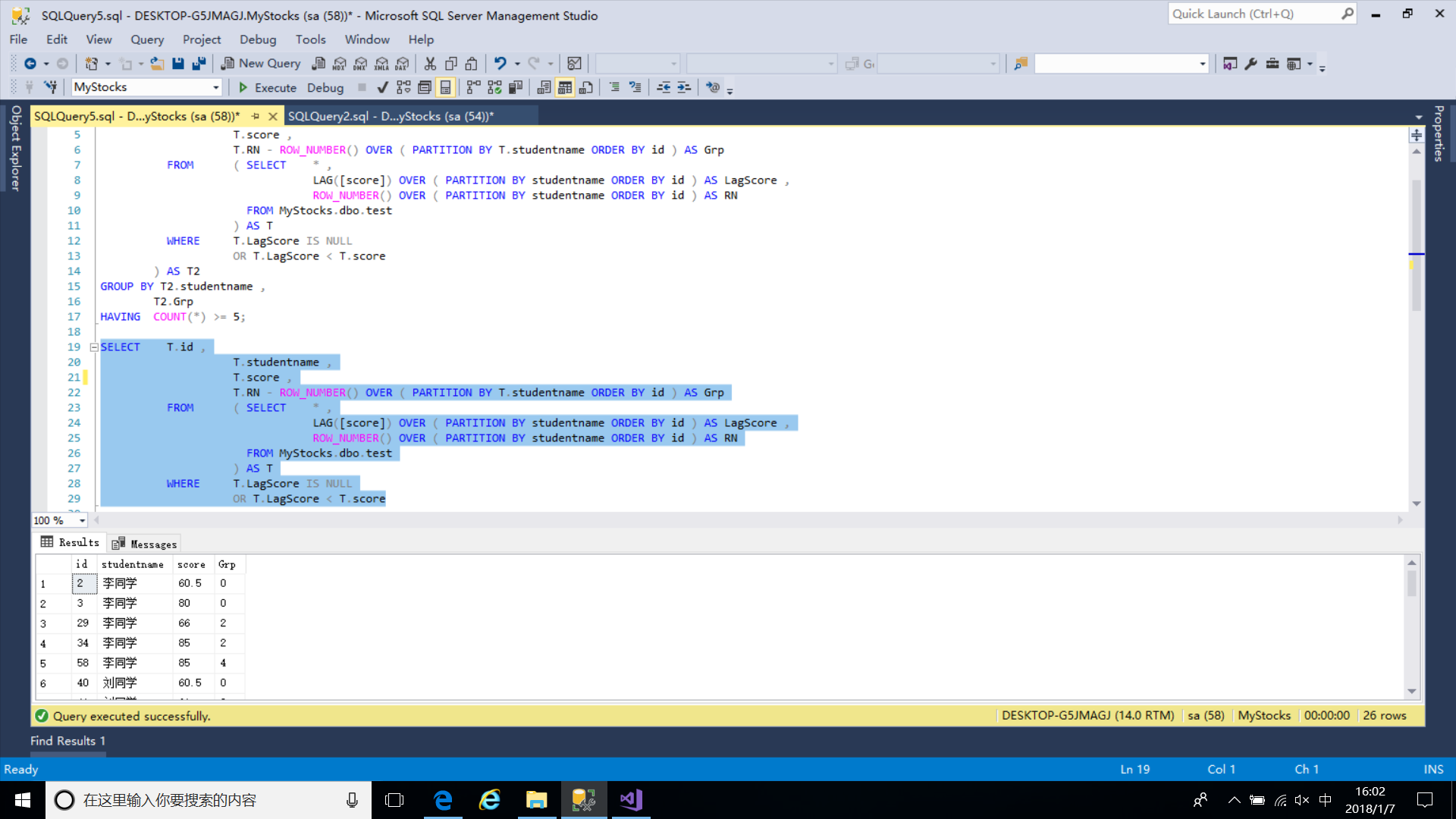

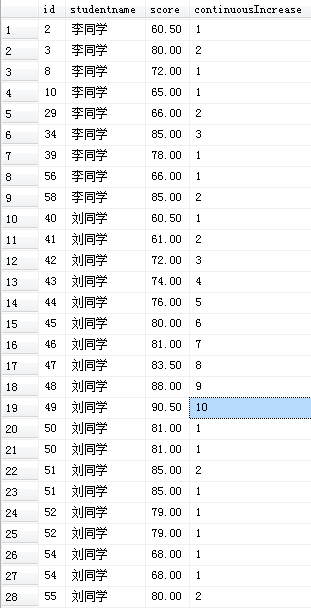
DECLARE @continuous INT; --连续增加的次数
DECLARE @studentname NVARCHAR(10); --人名
DECLARE @score DECIMAL(12,2) --分数
SET @continuous=0;
SET @studentname='';
SET @score=0;
SELECT * ,
1 AS continuousIncrease
INTO #temp
FROM #T
ORDER BY studentname,id;
UPDATE #temp
SET continuousIncrease = @continuous ,
@continuous = CASE WHEN @studentname <> studentname THEN 1
WHEN @score < score THEN @continuous + 1
ELSE 1
END ,
@score = score ,
@studentname = studentname;
SELECT * FROM #tempif not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
GO
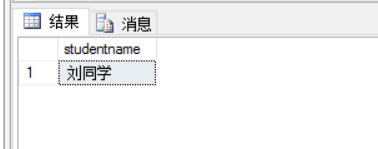
SELECT DISTINCT
T2.studentname
FROM ( SELECT T.id ,
T.studentname ,
T.score ,
T.RN
- ROW_NUMBER() OVER ( PARTITION BY T.studentname ORDER BY id ) AS Grp
FROM ( SELECT * ,
LAG([score]) OVER ( PARTITION BY studentname ORDER BY id ) AS LagScore ,
ROW_NUMBER() OVER ( PARTITION BY studentname ORDER BY id ) AS RN
FROM #T
) AS T
WHERE T.LagScore IS NULL
OR T.LagScore < T.score
) AS T2
GROUP BY T2.studentname ,
T2.Grp
HAVING COUNT(*) >= 10;
/*
studentname
刘同学
*/
-- 初始化测试数据
declare @tb table(id int,StudentName nvarchar(20),Score decimal(38,2))
insert into @tb(id,StudentName,Score)
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
-- 测试数据填充完毕
;with t as (
select *,row_number() over(partition by StudentName order by id) as rowid from @tb
),tt as (
select *,0 as times from t a where not exists(select top 1 1 from t where a.rowid=rowid+1 and a.Score>=Score and a.StudentName=StudentName)
union all
select a.*,b.times+1 as times from t a,tt b where a.StudentName=b.StudentName and a.rowid=b.rowid+1 and a.Score>b.Score
)
select StudentName,max(times) as 最大提升成绩次数 from tt group by StudentName

;WITH
DATA AS(
SELECT *,
rid = ROW_NUMBER()OVER(PARTITION BY studentname ORDER BY id)
FROM #t
),
SGRP AS(
SELECT A.*,
sgrp = CASE WHEN B.[score] < A.[score] THEN 1 ELSE 0 END
FROM DATA A
LEFT JOIN DATA B
ON A.studentname = B.studentname AND A.rid = B.rid + 1
)
/*-- >= SQL 2012 的版本可以用这个代替前面的 DATA + SGRP
SGRP AS(
SELECT *,
rid = ROW_NUMBER()OVER(PARTITION BY studentname ORDER BY id),
sgrp = CASE
WHEN [score] > MAX([score])OVER(
PARTITION BY studentname
ORDER BY id ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING)
THEN 1
ELSE 0 END
FROM #t
)
--*/
SELECT studentname, MIN(id) as 首次提升id, MAX(id) as 最后提升id, COUNT(*) as 提升次数
FROM(
SELECT *,
gid = rid - ROW_NUMBER()OVER(PARTITION BY studentname, sgrp ORDER BY id)
FROM SGRP
WHERE sgrp = 1
) DATA
GROUP BY studentname, gid
HAVING COUNT(*) >= 3
;-- 达到累计提升次数的每个截止 id(如果只要名称,用 DISTINCT)
DECLARE @times int = 4;
SELECT *
FROM #t A
WHERE EXISTS(
SELECT MIN(V), MAX(V), COUNT(*) FROM(
SELECT v
= ROW_NUMBER()OVER(ORDER BY BB.id DESC)
- DENSE_RANK()OVER(ORDER BY BB.score DESC)
FROM(
SELECT TOP(@times) * FROM #t BB
WHERE BB.studentname = A.studentname AND BB.id <= A.id
ORDER BY BB.id DESC
) BB
)X
HAVING COUNT(*) = @times AND MIN(v) = MAX(v) AND MIN(v) = 0
)
ORDER BY A.studentname, A.id

if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
Go
with cte_1
as
(select *,
ROW_NUMBER() over (PARTITION by studentname order by id) as seq_1
from #t)
select studentname
from
(select *,ROW_NUMBER() OVER (partition by studentname,diff order by seq_1) as seq_2
from
(select A.*,case when A.score -isnull(B.score,0)>0 then 1 else 0 end as diff from cte_1 A
left join cte_1 B ON A.seq_1-1=B.seq_1 and A.studentname=B.studentname) as A) as A
group by studentname,seq_1-seq_2
having COUNT(*)>=10
-- 测试数据
if not object_id(N'Tempdb..#T') is null drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2, N'李同学',60.5 union all
select 3, N'李同学',80 union all
select 8, N'李同学',72 union all
select 10, N'李同学',65 union all
select 29, N'李同学',66 union all
select 34, N'李同学',85 union all
select 39, N'李同学',78 union all
select 56, N'李同学',66 union all
select 58, N'李同学',85 union all
select 40, N'刘同学',60.5 union all
select 41, N'刘同学',61 union all
select 42, N'刘同学',72 union all
select 43, N'刘同学',74 union all
select 44, N'刘同学',76 union all
select 45, N'刘同学',66.66 union all
select 46, N'刘同学',81 union all
select 47, N'刘同学',83.5 union all
select 48, N'刘同学',88 union all
select 49, N'刘同学',90.5 union all
select 50, N'刘同学',81 union all
select 51, N'刘同学',85 union all
select 52, N'刘同学',79 union all
select 54, N'刘同学',68 union all
select 55, N'刘同学',80 union all
select 50, N'刘同学',81 union all
select 51, N'刘同学',85 union all
select 52, N'刘同学',79 union all
select 54, N'刘同学',68 union all
select 55, N'刘同学',80 union all
select 1, N'王同学',78 union all
select 5, N'王同学',75 union all
select 6, N'王同学',74 union all
select 12, N'王同学',79.5 union all
select 25, N'王同学',85 union all
select 38, N'王同学',86 union all
select 53, N'王同学',85 union all
select 60, N'王同学',86
GO
-- 查询
declare @studentname nvarchar(10),@score decimal(12,2),
@i int, @re nvarchar(max)
;
SET @re = N'';
with data as(select * from(values
('a', 1, 1), ('a', 2, 3), ('a', 3, 2), ('a', 4, 4), ('a', 5, 5)
)d(studentname, id, score)
)
SELECT
@i = CASE
WHEN @studentname = studentname THEN
CASE WHEN @score < score -- 如果成绩相同也算提升,则用 <=
THEN @i + 1 ELSE 1 END
ELSE 1
END,
@re = CASE WHEN @i >= 4 THEN -- 连续提升达到指定次数则记录到结果
@re + N'<r id=' + QUOTENAME(id, N'"') + N' v=' + QUOTENAME(@i, N'"')
+ '><![CDATA[' + @studentname + N']]></r>'
ELSE @re END,
@studentname = studentname,
@score = score
FROM #t
ORDER BY studentname, id
;
-- 名单在 @re 中,下面这个查询显示名单及对应累计的明细
SELECT *
FROM(
SELECT
T.c.value('text()[1]', 'nvarchar(10)') as studentname,
T.c.value('@v', 'int') as 累计提升次数,
T.c.value('@id', 'int') as 截止id
FROM( SELECT CONVERT(xml, @re) )RE(x)
CROSS APPLY RE.x.nodes('/r') T(c)
) R
CROSS APPLY(
SELECT TOP (R.累计提升次数)
D.id as detial_id, D.score as detial_score
FROM #t D
WHERE D.studentname = R.studentname AND D.id <= R.截止id
ORDER BY D.id DESC
) DATA
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
GO
SELECT studentname rn
FROM ( SELECT * ,
RTRIM(ROW_NUMBER() OVER ( PARTITION BY studentname ORDER BY studentname, score )
- ROW_NUMBER() OVER ( PARTITION BY studentname ORDER BY studentname, id )) rn
FROM #T
) t
WHERE rn > 0
GROUP BY studentname
HAVING COUNT(1) >= 10;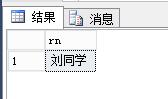

if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
--SQL server 2012+
;with t as (
select *,row_number()over(partition by studentname order by id) as newid,sign(score-LAG(score)over(partition by studentname order by id)) as a_d from #t
),tt as (
select *,newid-row_number()over(partition by studentname,a_d order by id) as d from t --order by studentname,newid
)
select studentname,d,count(0) from tt group by studentname,d having d=1 and count(0)>=9 ---d=-1就是下降
--SQL Server 2012以前版本
;with t1 as (
select *,row_number()over(partition by studentname order by id) as newid from #t
),t2 as (
select a.*,sign(a.score-isnull(b.score,a.score)) as a_d
from t1 as a left join t1 as b on a.studentname=b.studentname and b.newid=a.newid-1
)
,tt as (
select *,newid-row_number()over(partition by studentname,a_d order by id) as d from t2
)
select studentname,d,count(0) from tt group by studentname,d having d=1 and count(0)>=9
+-------------+---+---+
| studentname | d | |
+-------------+---+---+
| 刘同学 | 1 | 9 |
+-------------+---+---+

if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T(id int,studentname nvarchar(10),[score] decimal(12,2))
Insert #T
select 2,'李同学',60.5 union all
select 3,'李同学',80 union all
select 8,'李同学',72 union all
select 10,'李同学',65 union all
select 29,'李同学',66 union all
select 34,'李同学',85 union all
select 39,'李同学',78 union all
select 56,'李同学',66 union all
select 58,'李同学',85 union all
select 40,'刘同学',60.5 union all
select 41,'刘同学',61 union all
select 42,'刘同学',72 union all
select 43,'刘同学',74 union all
select 44,'刘同学',76 union all
select 45,'刘同学',80 union all
select 46,'刘同学',81 union all
select 47,'刘同学',83.5 union all
select 48,'刘同学',88 union all
select 49,'刘同学',90.5 union all
select 50,'刘同学',81 union all
select 51,'刘同学',85 union all
select 52,'刘同学',79 union all
select 54,'刘同学',68 union all
select 55,'刘同学',80 union all
select 1,'王同学',78 union all
select 5,'王同学',75 union all
select 6,'王同学',74 union all
select 12,'王同学',79.5 union all
select 25,'王同学',85 union all
select 38,'王同学',86 union all
select 53,'王同学',85 union all
select 60,'王同学',86
--测试数据结束
--只需要自连接一下就可以算出来了
;WITH cte AS (
SELECT * ,ROW_NUMBER() OVER(PARTITION BY studentname ORDER BY id) AS rn FROM #t
),
cte2 AS (
SELECT b.studentname,b.rn-ROW_NUMBER() OVER(PARTITION BY b.studentname ORDER BY b.rn ) AS new_rn
FROM cte a
right JOIN cte b ON a.rn=b.rn+1 AND a.studentname=b.studentname
WHERE a.score>b.score OR a.score IS NULL
)
SELECT studentname FROM cte2
WHERE new_rn=0
GROUP BY studentname
HAVING COUNT(1)>=9