22,297
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


DECLARE @re varchar(100);
SET @re = '';
WITH tbl(id, Code, Name) AS
(
SELECT 1, '00', 'AA' UNION ALL
SELECT 2, '0000', 'BB' UNION ALL
SELECT 3, '000000', 'CC' UNION ALL
SELECT 4, '00000000', 'DD' UNION ALL
SELECT 5, '0000000000', 'EE' UNION ALL
SELECT 6, '000000000000', 'FF' UNION ALL
SELECT 7, '00000000000000', 'GG' UNION ALL
SELECT 8, '0000000000000000', 'HH'
),
CODE AS(
SELECT Code = A.code2, LEN(A.code2) as l2, LEN(a.code1) as l1
FROM(SELECT
(SELECT code FROM tbl WHERE id = 2) as code1,
(SELECT code FROM tbl WHERE id = 6) as code2
)A
),
CODES AS(
SELECT * FROM CODE
UNION ALL
SELECT LEFT(Code, l2 - 2), l2 - 2, l1 FROM CODES WHERE l1 < l2
)
SELECT @re = @re + '-' + DATA.Name
FROM CODES, tbl DATA
WHERE CODES.Code = DATA.Code
ORDER BY DATA.Code
;
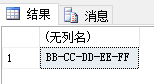
SELECT STUFF(@re, 1, 1, '');
DECLARE @code varchar(100), @re varchar(500);
DECLARE @id1 int, @id2 int;
SELECT @id1=2, @id2=8;
;WITH tbl(id, Code, Name) AS
(
SELECT 1, '00', 'AA' UNION ALL
SELECT 2, '0000', 'BB' UNION ALL
SELECT 3, '000000', 'CC' UNION ALL
SELECT 4, '00000000', 'DD' UNION ALL
SELECT 5, '0000000000', 'EE' UNION ALL
SELECT 6, '000000000000', 'FF' UNION ALL
SELECT 7, '00000000000000', 'GG' UNION ALL
SELECT 8, '0000000000000000', 'HH'
)
SELECT
@re = CASE
WHEN id = @id2 THEN Name
WHEN code = @code THEN name + '-' + @re
ELSE @re
END,
@code = CASE
WHEN id = @id1 THEN NULL
WHEN id = @id2 THEN LEFT(code, LEN(code) -2)
ELSE LEFT(code, LEN(code) -2)
END
FROM tbl
ORDER BY code DESC
;
SELECT @re

DECLARE @str NVARCHAR(max)='2,6'
;WITH tbl(id, Code, Name) AS
(
SELECT 1, '00', 'AA' UNION ALL
SELECT 2, '0000', 'BB' UNION ALL
SELECT 3, '000000', 'CC' UNION ALL
SELECT 4, '00000000', 'DD' UNION ALL
SELECT 5, '0000000000', 'EE' UNION ALL
SELECT 6, '000000000000', 'FF' UNION ALL
SELECT 7, '00000000000000', 'GG' UNION ALL
SELECT 8, '0000000000000000', 'HH'
)
SELECT STUFF((
SELECT '-'+tbl.Name
FROM tbl
WHERE id BETWEEN SUBSTRING(@str, 0, CHARINDEX(',', @str))
AND SUBSTRING(@str, CHARINDEX(',', @str)+1,
LEN(@str) - CHARINDEX(',', @str)) FOR XML PATH('')),1,1,'')