111,129
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享FileStream fs = File.OpenRead(file);
var buffer = new byte[fs.Length];
fs.Read(buffer, 0, buffer.Length);
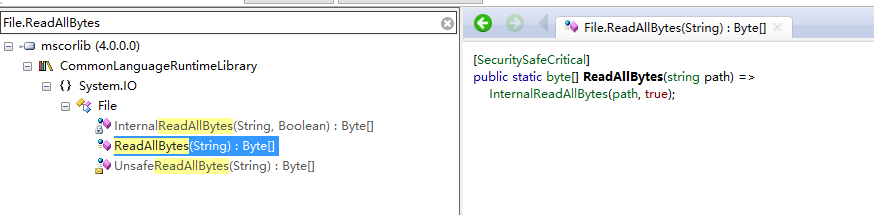
var buffer = File.ReadAllBytes(file);


public static byte[] ReadFile(string file)
{
var result = new MemoryStream();
var fs = File.OpenRead(file);
var buffer = new byte[1024 * 8];
var len = 0;
while ((len = fs.Read(buffer, 0, buffer.Length)) > 0)
result.Write(buffer, 0, len);
return result.ToArray();
}public static IEnumerable<byte[]> ReadFile(string file)
{
using (var fs = File.OpenRead(file))
{
var buffer = new byte[1024 * 20];
var len = 0;
while ((len = fs.Read(buffer, 0, buffer.Length)) > 0)
{
var result = new byte[len];
buffer.CopyTo(result, len);
yield return result;
}
}
}fs.Read(buffer, 0, buffer.Length);
[System.Security.SecurityCritical]
[ResourceExposure(ResourceScope.Machine)]
[ResourceConsumption(ResourceScope.Machine)]
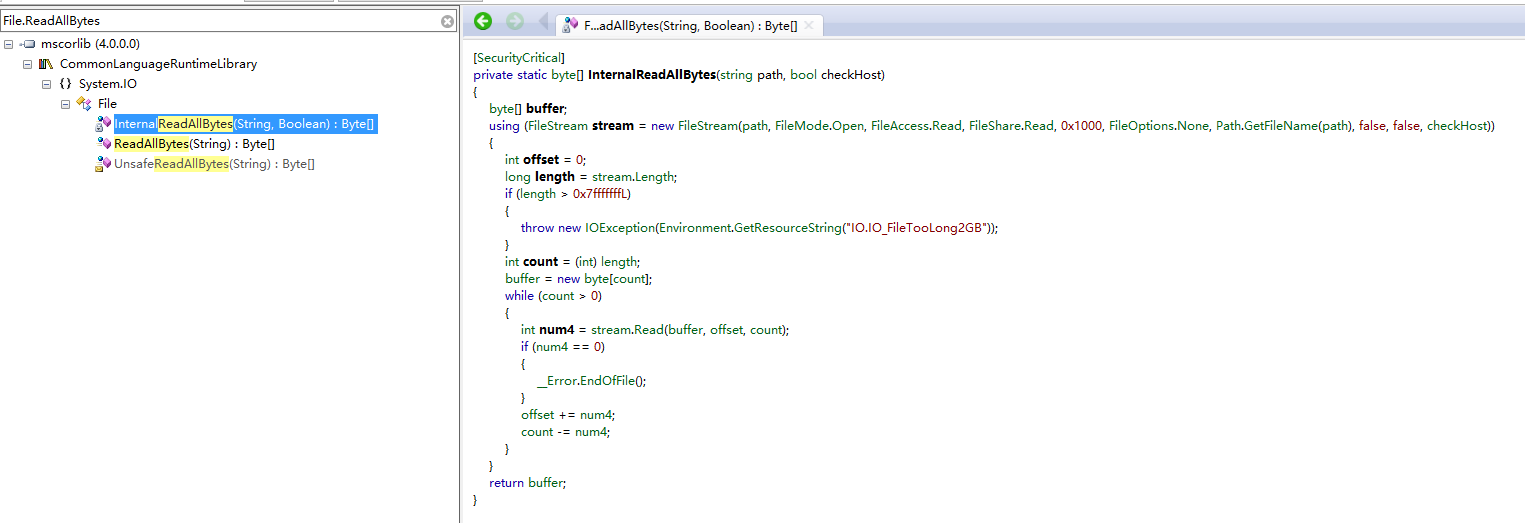
private static byte[] InternalReadAllBytes(String path, bool checkHost)
{
byte[] bytes;
using(FileStream fs = new FileStream(path, FileMode.Open, FileAccess.Read, FileShare.Read,
FileStream.DefaultBufferSize, FileOptions.None, Path.GetFileName(path), false, false, checkHost)) {
// Do a blocking read
int index = 0;
long fileLength = fs.Length;
if (fileLength > Int32.MaxValue)
throw new IOException(Environment.GetResourceString("IO.IO_FileTooLong2GB"));
int count = (int) fileLength;
bytes = new byte[count];
while(count > 0) {
int n = fs.Read(bytes, index, count);
if (n == 0)
__Error.EndOfFile();
index += n;
count -= n;
}
}
return bytes;
}