社区
Spark
帖子详情
生成布隆过滤器后,广播到各节点,如何用它实现对表的过滤?
chen_8703
2018-01-17 10:43:14
生成布隆过滤器后,广播到各节点,如何用它实现对表的过滤?
...全文
208
回复
打赏
收藏
生成布隆过滤器后,广播到各节点,如何用它实现对表的过滤?
生成布隆过滤器后,广播到各节点,如何用它实现对表的过滤?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
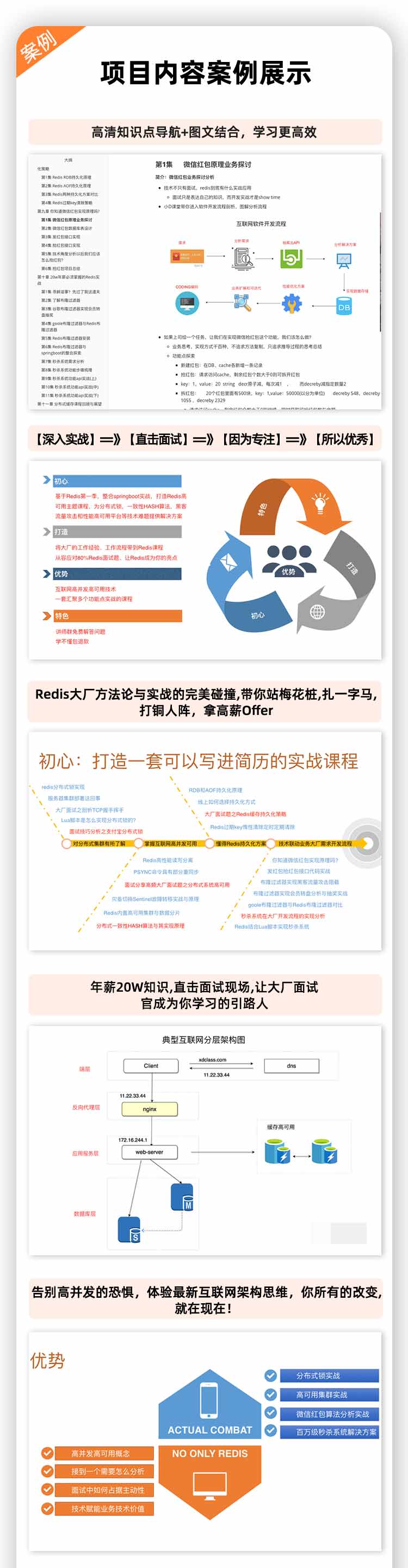
19年录制Redis实战教程 高可用秒杀分布式锁
布隆
过滤
器
实战 SpringBoot教程整合
JehanRio‘s 计算机后端岗位面经汇总(燃烧自己,最干货的一篇 —— 包含C++、408、数据库、Linux、场景题、智力题等等)
布隆
过滤
器
很难
实现
删除操作。
布隆
过滤
器
主要是为了防止redis缓存击穿问题(前端要查询一个数据,但是redis没有这个数据,就会去数据库查询,数据库可能承受不了这么大的流量就挂掉了)。有了
布隆
过滤
器
,就能判断...
【实习记录】第7周 2023.08.07-2023.08.11
在事务A开始之前,或...:将所有存在的key提前存入
布隆
过滤
器
,客户端发送的请求在到达缓存层之前,先经过
布隆
过滤
器
,看请求的key是否在
过滤
器之中,如果不在,则直接返回空值,若存在,再继续访问缓存层和存储层。
dsg_10 Hbase
HbaseHBase的介绍HBase的特征HBase的存储机制HBase的搭建 HBase的介绍 HBase是基于hadoop的数据库,分布式可伸缩(可任意增加或减少
节点
...块缓存和
布隆
过滤
器
用于实时查询 通过服务器端
过滤
器
实现
查询预测 支持XML, P
HBase:NoSQL数据库(END-6.HBase的优化)
布隆
过滤
器
5.内存优化6.基础优化6.1 允许在HDFS的文件中追加内容6.2 优化DataNode允许的最大文件打开数6.3 优化延迟高的数据操作的等待时间6.4 优化数据的写入效率6.5 设置RPC监听数量6.6 优化HStore文件大小6.7 ...
Spark
1,258
社区成员
1,168
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章







 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
