27,580
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







use Tempdb
go
--> --> 中国风(Roy)生成測試數據
if not object_id(N'Tempdb..#Data') is null
drop table #Data
Go
Create table #Data([Code] nvarchar(21),[Content] nvarchar(28))
Insert #Data
select N'a',N'百富美我是谁' union all
select N'b',N'百度一下我就知道' union all
select N'c',N'百度一下我就什么' union all
select N'd',N'谷歌一下我就知道'
GO
DECLARE @Str NVARCHAR(100) ='百度一下下我就知道'
, @Len TINYINT =0;
SET @Len=LEN(@Str);
WITH TNum (Num)
AS
(
SELECT TOP 100
ROW_NUMBER() OVER (ORDER BY RAND())
FROM syscolumns AS a
, syscolumns AS b)
, TNum2 (Condition)
AS
(
SELECT DISTINCT
SUBSTRING(@Str, Num, 1)
FROM TNum
WHERE Num<=@Len)
SELECT *
, CAST(b.CountQty * 100.0 / (SELECT COUNT(*) FROM TNum2) AS NUMERIC(5, 2)) AS 权重
FROM #Data AS DT
CROSS APPLY
(SELECT COUNT(*)
FROM TNum2
WHERE DT.[Content] LIKE '%'+Condition+'%') b(CountQty)
WHERE b.CountQty>0
ORDER BY 4 DESC;
if OBJECT_ID(N'tempdb.dbo.#T') is not null
drop table #T
go
create table #T(col nvarchar(max))
insert into #T
select '百富美我是谁' union all
select '百度一下我就知道' union all
select '百度一下我就什么' union all
select '谷歌一下我就知道'
declare @str nvarchar(max)
set @str='百度一下我就知道'
select col,(COUNT(*)*1.0)/MAX(qty_char) as mathc_percent
from
(select COUNT(1) over (partition by 1) as qty_char,SUBSTRING(@str,number,1) as single_char
from master.dbo.spt_values where LEN(@str)>=number and type='p' and number>0) as A
join
(select col,SUBSTRING(col,number,1) as match_char
from master.dbo.spt_values A
join #T B ON LEN(col)>=number
where type='p' and number>0) as B on A.single_char=B.match_char
group by col


CREATE FUNCTION dbo.MatchPercent
(
@SplitString nvarchar(max)
)
RETURNS @SplitStringsTable TABLE
(
[id] int identity(1,1),
[value] nvarchar(max)
)
AS
BEGIN
DECLARE @CurrentIndex int;
DECLARE @len INT = len(@SplitString);
DECLARE @ReturnText NVARCHAR(20)
SELECT @CurrentIndex=1;
WHILE(@CurrentIndex<=@len)
BEGIN
SELECT @ReturnText=substring(@SplitString,1,1);
INSERT INTO @SplitStringsTable([value]) VALUES(@ReturnText);
SET @SplitString = STUFF(@SplitString,1,1,'')
SET @CurrentIndex = @CurrentIndex+1
END
RETURN;
END
GO
--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([col1] nvarchar(21),[col2] nvarchar(28))
Insert #T
select N'a',N'百富美我是谁' union all
select N'b',N'百度一下我就知道' union all
select N'c',N'百度一下我就什么' union all
select N'd',N'谷歌一下我就知道'
Go
--测试数据结束
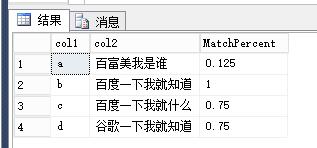
DECLARE @str NVARCHAR(max)='百度一下我就知道'
SELECT * ,
( CONVERT(FLOAT, ( SELECT COUNT(1)
FROM dbo.MatchPercent(col2) t1
JOIN dbo.MatchPercent(@str) t2 ON t2.id = t1.id
AND t2.value = t1.value
)) / ( SELECT COUNT(1)
FROM dbo.MatchPercent(@str)
) ) AS MatchPercent
FROM #T