


17,377
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



with DAILYRECORD_MONTH as (select t.* from platform_system_dailyrecord.DAILYRECORD_2018_01 t order by CREATE_TIME desc)
Select * From DAILYRECORD_MONTH t Where ROWNUM <=20
with DAILYRECORD_MONTH as (select t.* from platform_system_dailyrecord.DAILYRECORD_2018_01 t order by CREATE_TIME desc)
select * from(
Select * From DAILYRECORD_MONTH t Where ROWNUM <=20
)t
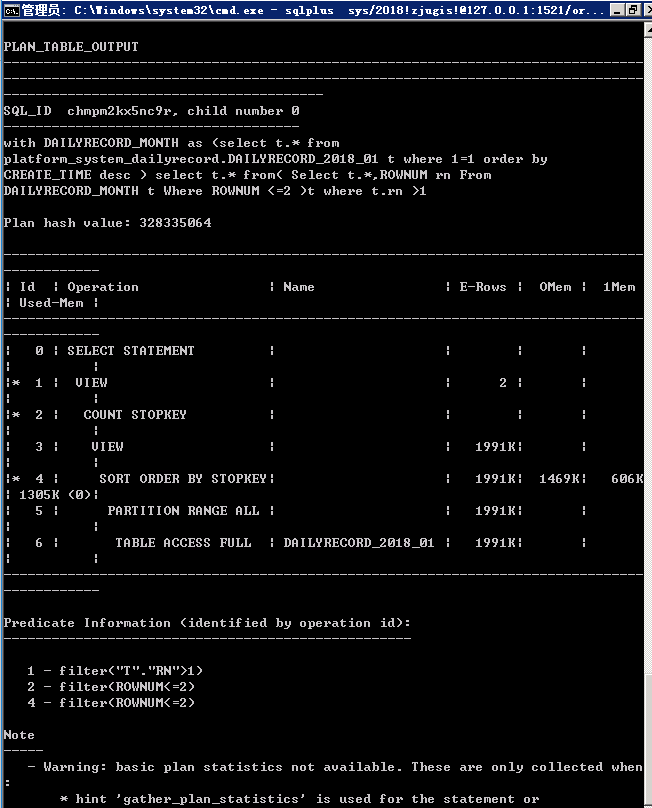
set linesize 200
set pagesize 500
with DAILYRECORD_MONTH as (select t.* from DAILYRECORD_2018_01 t where 1=1 order by CREATE_TIME desc )
select /*+gather_plan_statistics*/t.* from(
Select t.*,ROWNUM rn From DAILYRECORD_MONTH t Where ROWNUM <=28
)t where t.rn >14;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
-- Create table
create table DAILYRECORD_2017_10
(
DAILYRECORD_ID NVARCHAR2(36) not null,
SYSTEM_NAME NVARCHAR2(64),
SYSTEM_VERSION NVARCHAR2(64),
MODULE_NAME NVARCHAR2(64),
REQUEST_URL NVARCHAR2(2000),
REQUEST_TYPE NVARCHAR2(32),
REQUEST_IP NVARCHAR2(32),
REQUEST_USERNAME NVARCHAR2(64),
REQUEST_PARAMS NVARCHAR2(2000),
REQUEST_TIMESPAN INTEGER,
RESPONSE_FLAG INTEGER,
REMARK NVARCHAR2(1024),
CREATE_TIME DATE,
USER_MODULE NVARCHAR2(255),
OPERATION_NAME NVARCHAR2(255),
OPERATION_TYPE INTEGER,
USER_LOG_FLAG INTEGER,
DESCRIPTION NVARCHAR2(1024)
)
partition by range (CREATE_TIME)
interval (numtodsinterval(1,'DAY'))
(
partition p0101 values less than (to_date('2018-01-02','yyyy-mm-dd'))
)
tablespace PLATFORM_SYSTEM_DAILYRECORD
pctfree 10
initrans 1
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
-- Create/Recreate primary, unique and foreign key constraints
alter table DAILYRECORD_2017_10
add constraint DAILYRECORD_2017_10_PK_ID primary key (DAILYRECORD_ID)
using index
tablespace PLATFORM_SYSTEM_DAILYRECORD
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
-- Create/Recreate indexes
create index DAILYRECORD_2017_10_IN_CT on DAILYRECORD_2017_10 (CREATE_TIME)
tablespace PLATFORM_SYSTEM_DAILYRECORD
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
-- Grant/Revoke object privileges
grant select on DAILYRECORD_2017_10 to NO_PAY_USER;
with DAILYRECORD_MONTH as (select t.* from DAILYRECORD_2018_01 t where 1=1 order by CREATE_TIME desc )
select t.* from(
Select t.*,ROWNUM rn From DAILYRECORD_MONTH t Where ROWNUM <=28
)t where t.rn >14
with DAILYRECORD_MONTH as (select t.* from DAILYRECORD_2018_01 t where 1=1 order by CREATE_TIME desc )
Select t.*,ROWNUM rn From DAILYRECORD_MONTH t Where ROWNUM <=55

