

37,740
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
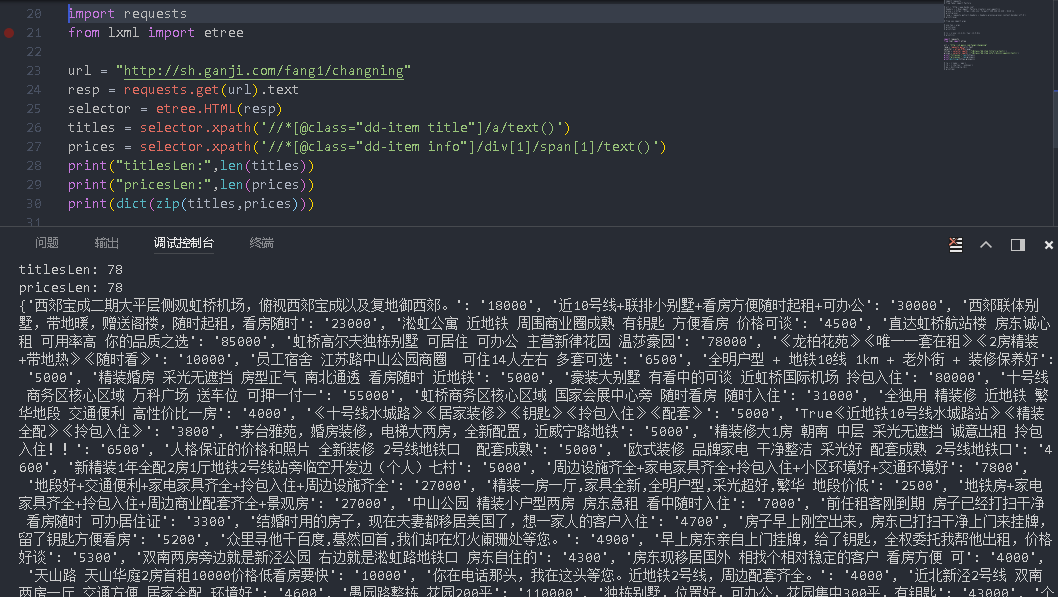 最后给个建议 你看试试爬下其他网站 看是不是也有这个问题[/quote]
我用你的代码试了下,还是不行,换了个网站倒是可以。
而且我发现read到的网页就是不全的。。。
最后给个建议 你看试试爬下其他网站 看是不是也有这个问题[/quote]
我用你的代码试了下,还是不行,换了个网站倒是可以。
而且我发现read到的网页就是不全的。。。 最后给个建议 你看试试爬下其他网站 看是不是也有这个问题
最后给个建议 你看试试爬下其他网站 看是不是也有这个问题

import requests
from lxml import etree
url = "http://sh.ganji.com/fang1/changning"
resp = requests.get(url).text
selector = etree.HTML(resp)
list = selector.xpath('//*[@class="dd-item info"]/div[1]/span[1]/text()')
print("price:",list)
print("len:",len(list))


