



37,719
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import requests
import re
from bs4 import BeautifulSoup
import xlwt #导入相关库
all_info_list = [] #定义一个空列表,用来存储爬虫数据。
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.74 Safari/537.36'} #请求头
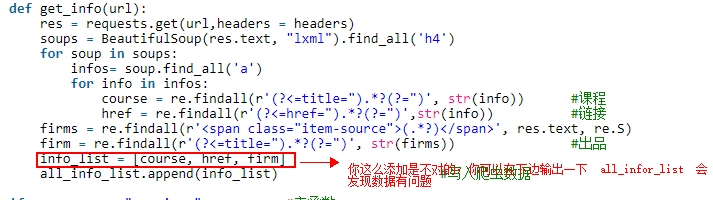
def get_info(url):
res = requests.get(url,headers = headers)
soups = BeautifulSoup(res.text, "lxml").find_all('h4')
for soup in soups:
infos= soup.find_all('a')
for info in infos:
course = re.findall(r'(?<=title=").*?(?=")', str(info)) #课程
href = re.findall(r'(?<=href=").*?(?=")',str(info)) #链接
firms = re.findall(r'<span class="item-source">(.*?)</span>', res.text, re.S)
firm = re.findall(r'(?<=title=").*?(?=")', str(firms)) #出品
info_list = [course, href, firm]
all_info_list.append(info_list) #写入爬虫数据
if __name__ == "__main__": #主函数
urls = ['https://ke.qq.com/course/list?mt=1001&st=2002&tt=3019&page={}'.format(i) for i in range(1,10)]
for url in urls:
get_info(url)
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('ke_qq')
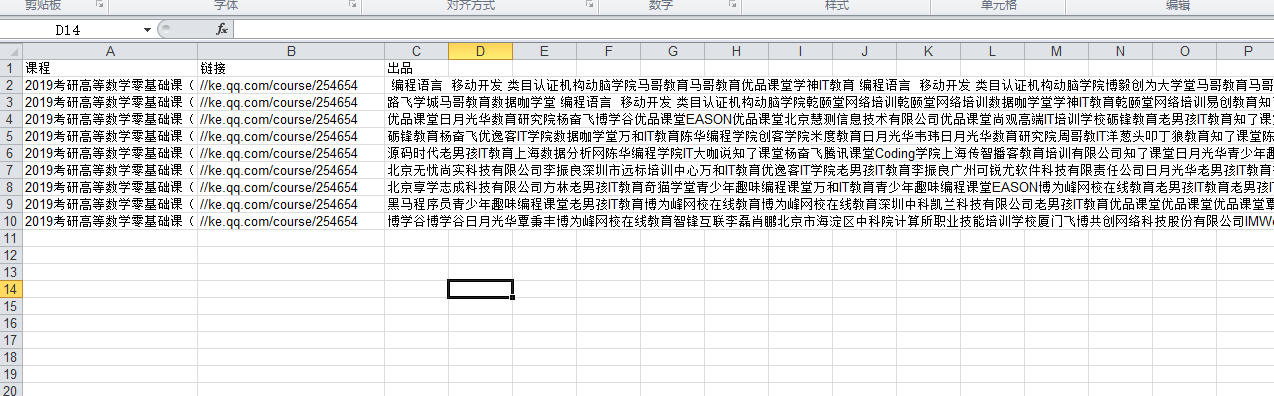
head = ['课程','链接','出品'] #表头
for h in range(len(head)):
sheet.write(0,h,head[h]) #写入表头
i = 1
for list in all_info_list:
j = 0
for data in list:
sheet.write(i,j,data)
j+=1
i+=1
book.save('E:\spiderfile\ke.xls')