24,852
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享void* memcpy_copy_align(void* dst, const void* src, size_t count) {
assert(dst);
assert(src);
int *dalign, *salign;
int nchunks, slice;
char* dstp = (char*)dst;
const char* srcp = (const char*)src;
if (dstp<srcp + count && dstp>srcp) {
dstp += count - 1;
srcp += count - 1;
for (; ((int)srcp & 3) != 0; count--) {
if (!count)
return dst;
*dstp-- = *srcp--;
}
*dstp = *srcp;
count--;
nchunks = count >> 2;
slice = count & 3;
if (nchunks) {
dalign = (int*)dstp;
salign = (int*)srcp;
while (nchunks--)
*--dalign = *--salign;
dstp = (char*)dalign;
srcp = (char*)salign;
}
while (slice--)
*--dstp = *--srcp;
}
else {
for (; ((int)srcp & 3) != 0; count--) {
if (!count)
return dst;
*dstp++ = *srcp++;
}
nchunks = count >> 2;
slice = count & 3;
if (nchunks) {
dalign = (int*)dstp;
salign = (int*)srcp;
while (nchunks--)
*dalign++ = *salign++;
dstp = (char*)dalign;
srcp = (char*)salign;
}
while (slice--)
*dstp++ = *srcp++;
}
return dst;
}
void* memcpy_copy(void* dst, const void* src, size_t count) {
assert(dst);
assert(src);
int *dalign, *salign;
int nchunks, slice;
char* dstp = (char*)dst;
const char* srcp = (const char*)src;
nchunks = count >> 2;
slice = count & 3;
if (dstp<srcp + count && dstp>srcp) {
dstp += count;
srcp += count;
if (nchunks) {
dalign = (int*)dstp;
salign = (int*)srcp;
while (nchunks--)
*--dalign = *--salign;
dstp = (char*)dalign;
srcp = (char*)salign;
}
while (slice--)
*--dstp = *--srcp;
}
else {
if (nchunks) {
dalign = (int*)dstp;
salign = (int*)srcp;
while (nchunks--)
*dalign++ = *salign++;
dstp = (char*)dalign;
srcp = (char*)salign;
}
while (slice--)
*dstp++ = *srcp++;
}
return dst;
}void* memcpy_copy_a(void* dst, const void* src, size_t count) {
assert(dst);
assert(src);
char* dstp = (char*)dst;
const char* srcp = (const char*)src;
if (dstp<srcp + count && dstp>srcp) {
dstp += count;
srcp += count;
while (count--)
*--dstp = *--srcp;
}
else {
while (count--)
*dstp++ = *srcp++;
}
return dst;
}int main()
{
int i;
clock_t start;
int len = sizeof(char) * 1024 * 1024 * 512;
char* b = (char*)malloc(len + 2);
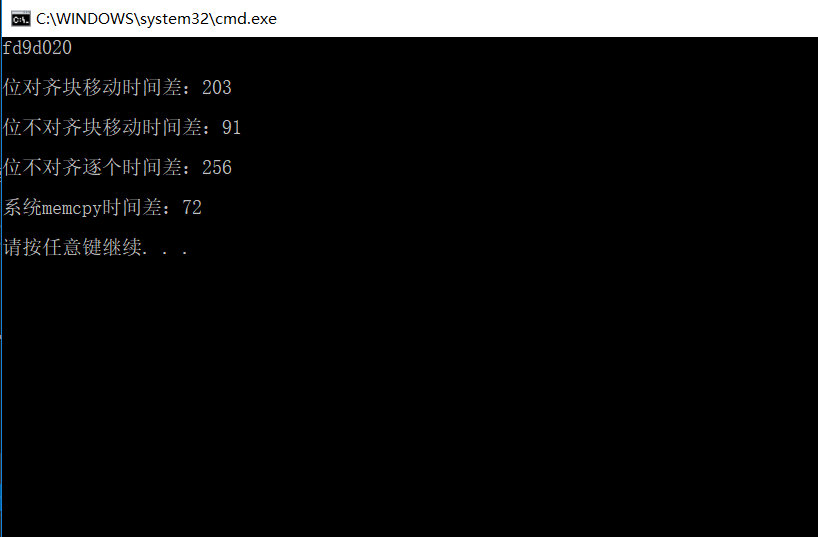
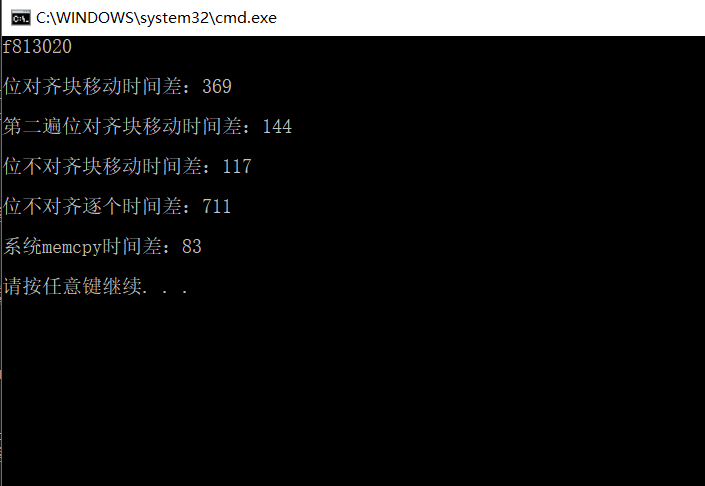
printf("%x\n", b);
start = clock();
memcpy_copy_align(b + 2, b, len);
printf("\n位对齐块移动时间差:%ld\n", clock() - start);
start = clock();
memcpy_copy(b + 2, b, len);
printf("\n位不对齐块移动时间差:%ld\n", clock() - start);
start = clock();
memcpy_copy_a(b + 2, b, len);
printf("\n位不对齐逐个时间差:%ld\n", clock() - start);
start = clock();
memcpy(b + 2, b, len);
printf("\n系统memcpy时间差:%ld\n\n", clock() - start);
return 0;
}