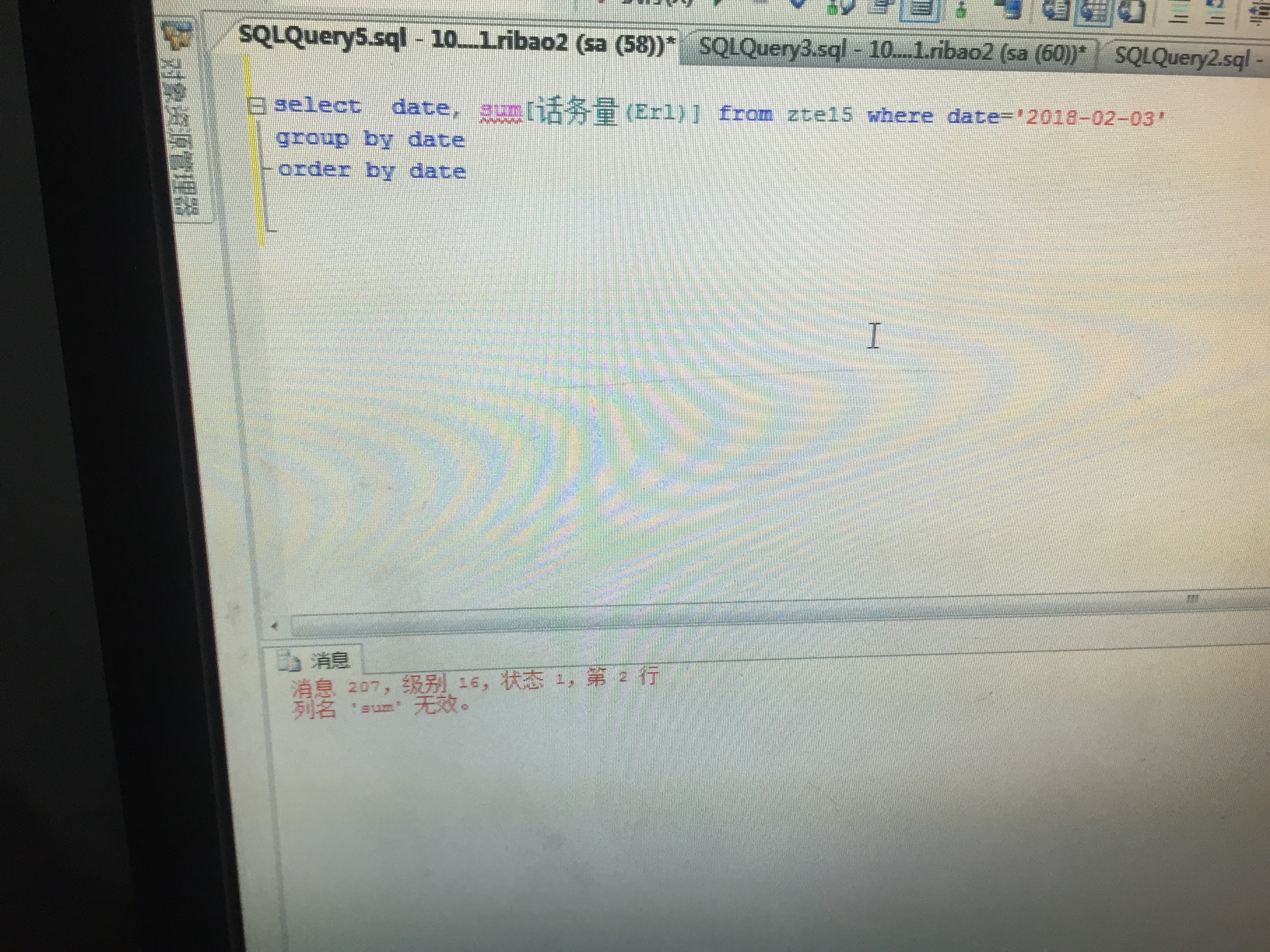
DECLARE @t table(num NUMERIC(18,4)) INSERT INTO @t (num) VALUES (1.1234 -- num - numeric(18, 4) ),(1.1234 -- num - numeric(18, 4) ) SELECT SUM(num) FROM @t /* (无列名) 2.2468 */
34,588
社区成员
254,588
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享