


22,297
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享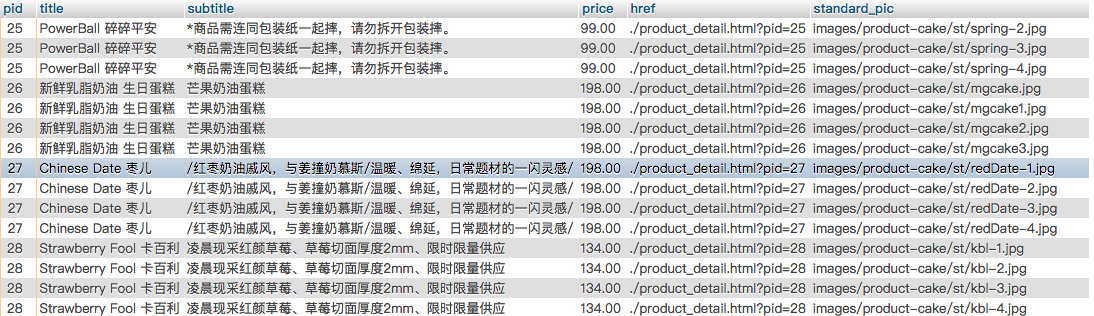

select p.pid,p.title,p.subtitle,p.price,p.href,m.standard_pic
FROM yc_product p
LEFT JOIN (
SELECT ROW_NUMBER()OVER(PARTITION BY m.pid ORDER BY standard_pic) AS seq,* FROM yc_product_pic m
) AS mm ON mm.seq=1 AND mm.pid=p.pid

SELECT p.pid,
p.title,
p.subtitle,
p.price,
p.href,
(SELECT TOP 1 m.standard_pic FROM yc_product_pic AS m WHERE p.pid=m.pid) AS standard_pic
FROM yc_product AS p
WHERE p.tid = 1



