社区
Linux/Unix社区
帖子详情
Linux上运行CRF++0.58,测试的文本过大时,没有model文件生成
小小小小郁
2018-03-07 06:31:02
如题,文本有24M,近180万的数据量,运行命令:crf_learn -f 8 -c 1.5 template msr_training.01.crf.txt model_file 之后
会出现这种情况,也不生成model了,面对1M大小的文件基本上是没有问题的,有大佬为我来解释下是为什么吗。。。使用的是Ubuntu14.04 ,内存是4个G
...全文
1154
6
打赏
收藏
Linux上运行CRF++0.58,测试的文本过大时,没有model文件生成
如题,文本有24M,近180万的数据量,运行命令:crf_learn -f 8 -c 1.5 template msr_training.01.crf.txt model_file 之后 会出现这种情况,也不生成model了,面对1M大小的文件基本上是没有问题的,有大佬为我来解释下是为什么吗。。。使用的是Ubuntu14.04 ,内存是4个G
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
6 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
LEOlws
2019-07-23
打赏
举报
回复
我用的个人电脑,只能将语料库控制在10W行,2个特征才行,关键是他没抛什么错误信息出来啊
qq_36573282
2019-03-22
打赏
举报
回复
1
二楼的应该是特征太多了,-f 参数提高一下,减少特征数就可以了
飞翔的猪哥
2019-01-15
打赏
举报
回复
1
CPU不够用,扔到服务器上。
qq_26720653
2018-12-10
打赏
举报
回复
我也遇到到过楼主一样的错误,我的解决方案可以参考一下 number of sentences:1 这里应该是语料没有处理好, 数量不应该是1,在句子和句子之间应该也要换行隔开 二楼的错误跟咱们不一样 你那是迭代一轮后退出,网上有帖子说解决办法是加参数
weixin_39671803
2018-06-13
打赏
举报
回复
.. 14700.. 14800.. 14900.. 15000.. 15100.. 15200.. 15300.. 15400.. 15500.. 15600.. 15700.. 15800.. 15900.. 16000.. 16100.. 16200.. 16300.. 16400.. 16500.. 16600.. 16700.. 16800.. 16900.. 17000.. 17100.. 17200.. 17300.. 17400.. 17500.. 17600.. 17700.. 17800.. 17900.. 18000.. 18100.. 18200.. 18300.. 18400.. 18500.. 18600.. 18700.. 18800.. 18900.. 19000.. Done!41.93 s Number of sentences: 19054 Number of features: 2159868 Number of thread(s): 1 Freq: 3 eta: 0.00010 C: 4.00000 shrinking size: 20 iter=0 terr=0.67958 serr=1.00000 act=2159868 obj=2531994.56328 diff=1.00000
weixin_39671803
2018-06-13
打赏
举报
回复
一样的问题,win下。也是没有 model 文件
【windows下
CRF
++
的安装与使用】
CRF
的工具有两种,一种是支持
Linux
环境的,一种是支持Windows环境的,大家可以自行根据自己的系统进行下载。 (在此我下载的是
CRF
++
0.54) 在windows下安装很简单,解压到某目录下即可。 在此附
CRF
理论及工具包...
CRF
++
入门学习
CRF
++
学习
CRF
++
进行中文分词实例
工具包:https://taku910.github.io/
crf
pp/#tips 语料:... 安装: 1)下载
linux
版本
CRF
++
包-----
CRF
++
-
0.58
.tar.gz,并解压。 2)cd
CRF
++
-
0.58
3)./configure 4)sudo make 5)sudo make i...
NLP之
CRF
++
安装及使用
目录 一、
CRF
简介
CRF
VS 词典统计分词
CRF
VS HMM,MEMM ...
CRF
分词原理 ...二、
CRF
++
工具包 ...
CRF
++
的安装(
linux
) ...
CRF
由John Lafferty最早用于NLP技术领域,其在NLP技术领域中主要用于
文本
标注...
Ubuntu下
CRF
++
中文分词实验(一)文档阅读 工具安装
文章目录介绍1、实验内容2、本文内容3、系列文章一、概念入门二、
CRF
++
文档简要阅读
CRF
++
的官方文档Introduction(介绍)Download (下载链接)Installation (安装说明)Usage (使用说明)Case studies (举例学习...
Linux/Unix社区
18,773
社区成员
11,463
社区内容
发帖
与我相关
我的任务
Linux/Unix社区
Linux/Unix社区 专题技术讨论区
复制链接
扫一扫
分享
社区描述
Linux/Unix社区 专题技术讨论区
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享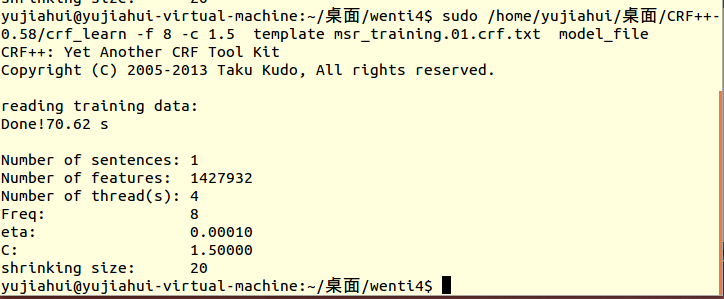 会出现这种情况,也不生成model了,面对1M大小的文件基本上是没有问题的,有大佬为我来解释下是为什么吗。。。使用的是Ubuntu14.04 ,内存是4个G
会出现这种情况,也不生成model了,面对1M大小的文件基本上是没有问题的,有大佬为我来解释下是为什么吗。。。使用的是Ubuntu14.04 ,内存是4个G




