

37,720
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
def downloadurl_with_retries(url,retries=2):
print('Downloading: %s'%url)
try:
with urllib.request.urlopen(url) as html:
return html.read()
except urllib.UrlError as e:
print('Download Error: %s'%e.reason)
if(retries>0):
if(hasattr(e,'code') and 500<=e.code<600):
##hasattr(object,name),判断对象object是否有名为name的属性或方法
print('Retry %d:'%retries)
return downloadurl(url,retries-1)
else:
return None
print(downloadurl_with_retries('http://httpstat.us/500'))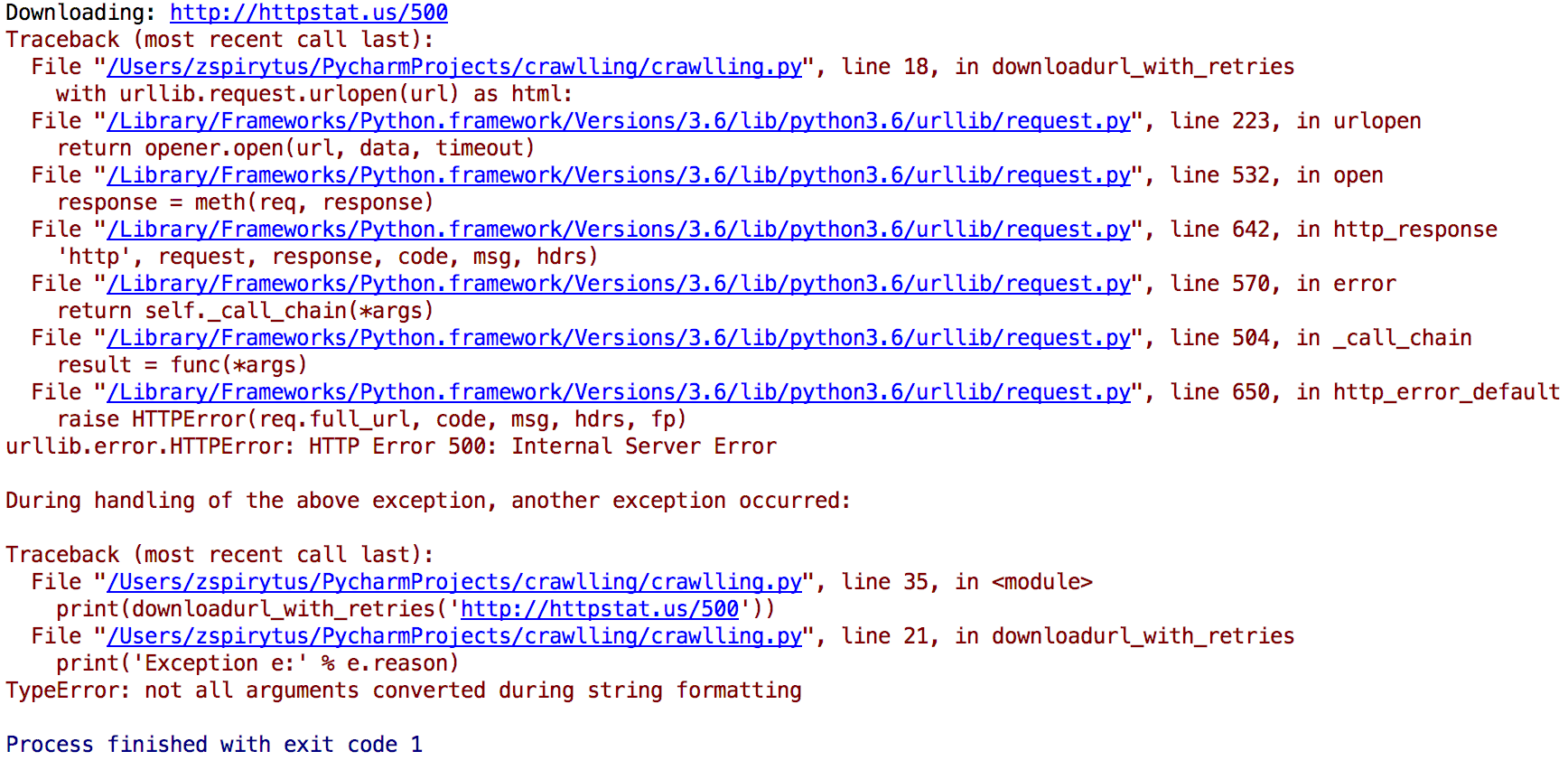

except urllib.UrlError as e:except urllib.error.HTTPError as e:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from urllib import request
url='http://httpstat.us/500'
def downloadurl_with_retries(url,retries=2):
print('Downloading: %s'%url)
try:
with request.urlopen(url) as html:
return html.read()
except Exception as e:
print('Download Error: %s'%e)
if(retries>0):
if(hasattr(e,'code') and 500<=e.code<600):
##hasattr(object,name),判断对象object是否有名为name的属性或方法
print('Retry %d:'%retries)
return downloadurl_with_retries(url,retries-1)
else:
return None
html=downloadurl_with_retries(url,2)
print(html)

