



34,577
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享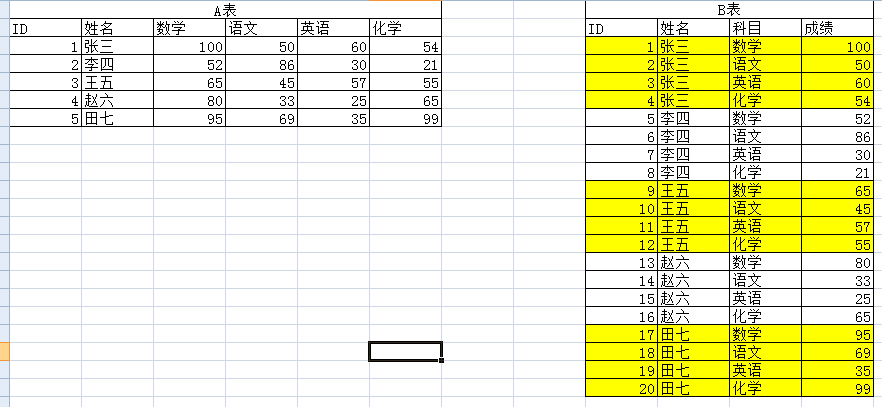




-- A表方式
;with t as (
select 1 as id,'张三' as 姓名,100 as 数学,50 as 语文,60 as 英语,54 as 化学
union all
select 2,'李四',52,86,30,21
union all
select 3,'王五',65,45,57,55
union all
select 4,'赵六',80,33,25,65
union all
select 5,'田七',95,69,35,99
)
select * from t a
where exists(
select * from t b
unpivot (value for field in (数学,语文,英语,化学)) c
where id=a.id and value>90
)
-- B表方式
;with t as (
select 1 as id,'张三' as 姓名,100 as 数学,50 as 语文,60 as 英语,54 as 化学
union all
select 2,'李四',52,86,30,21
union all
select 3,'王五',65,45,57,55
union all
select 4,'赵六',80,33,25,65
union all
select 5,'田七',95,69,35,99
),t1 as (
select row_number() over(order by id,field) as id,姓名,field as 科目,value as 成绩 from t a
unpivot (
value for field in (数学,语文,英语,化学)
) b
)
select 姓名,数学,语文,英语,化学 from (select 姓名,科目,成绩 from t1) a
pivot(
max(成绩) for 科目 in (数学,语文,英语,化学)
) p
where 姓名 in (
select distinct 姓名 from t1 where 成绩>90
)



