

65,211
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#ifndef RANDOMDQN_HPP
#define RANDOMDQN_HPP
#include <mlpack/prereqs.hpp>
#include <mlpack/core.hpp>
//#include <mlpack/methods/ann/ffn.hpp>
#include <mlpack/methods/ann/init_rules/gaussian_init.hpp>
#include <mlpack/methods/ann/layer/layer.hpp>
//#include <mlpack/methods/reinforcement_learning/q_learning.hpp>
//#include "veins/base/RLmethod/ffn.hpp"
//#include "veins/base/RLmethod/ann/init_rules/gaussian_init.hpp"
//#include "veins/base/RLmethod/ann/layer/layer.hpp"
#include "veins/base/RLmethod/myffn.hpp"
#include "veins/base/RLmethod/my_q_learning.hpp"
#include <mlpack/methods/reinforcement_learning/environment/mountain_car.hpp>
#include <mlpack/methods/reinforcement_learning/environment/cart_pole.hpp>
#include <mlpack/methods/reinforcement_learning/policy/greedy_policy.hpp>
#include <mlpack/core/optimizers/adam/adam_update.hpp>
#include <mlpack/core/optimizers/rmsprop/rmsprop_update.hpp>
#include <mlpack/methods/reinforcement_learning/training_config.hpp>
using namespace mlpack;
using namespace mlpack::ann;
using namespace mlpack::optimization;
using namespace mlpack::rl;
class randomdqn {
public:
// FFN tempmodel = new FFN(MeanSquaredError<>(), GaussianInitialization(0, 0.001));
// GreedyPolicy temppolicy = new GreedyPolicy(1.0,1000,0.1);
MYQLearning<CartPole, MYFFN, RMSPropUpdate, GreedyPolicy> agent;
public:
randomdqn() {
//! Test Double DQN in Cart Pole task.
// Set up the network.
MYFFN<MeanSquaredError<>, GaussianInitialization> model(MeanSquaredError<>(), GaussianInitialization(0, 0.001));
model.Add<Linear<>>(4, 20);
model.Add<ReLULayer<>>();
model.Add<Linear<>>(20, 20);
model.Add<ReLULayer<>>();
model.Add<Linear<>>(20, 2);
// Set up the policy and replay method.
GreedyPolicy<CartPole> policy(1.0,1000,0.1);
RandomReplay<CartPole> replayMethod(10, 10000);
TrainingConfig config;
config.StepSize() = 0.01;
config.Discount() = 0.9;
config.TargetNetworkSyncInterval() = 100;
config.ExplorationSteps() = 100;
config.DoubleQLearning() = false;
config.StepLimit() = 200;
// Set up the DQN agent.
// MYQLearning<CartPole, decltype(model), RMSPropUpdate, decltype(policy)> tempagent(
// std::move(config), std::move(model), std::move(policy),
// std::move(replayMethod));
//
// agent = tempagent;
agent = new MYQLearning<CartPole, decltype(model), RMSPropUpdate, decltype(policy)>(std::move(config), std::move(model), std::move(policy),std::move(replayMethod));
};
~randomdqn() {
};
};
#endif
/**
* Definition of the MYFFN class, which implements feed forward neural networks.
*/
#ifndef MLPACK_METHODS_ANN_MYFFN_HPP
#define MLPACK_METHODS_ANN_MYFFN_HPP
#include <mlpack/prereqs.hpp>
#include <mlpack/methods/ann/visitor/delete_visitor.hpp>
#include <mlpack/methods/ann/visitor/delta_visitor.hpp>
#include <mlpack/methods/ann/visitor/output_height_visitor.hpp>
#include <mlpack/methods/ann/visitor/output_parameter_visitor.hpp>
#include <mlpack/methods/ann/visitor/output_width_visitor.hpp>
#include <mlpack/methods/ann/visitor/reset_visitor.hpp>
#include <mlpack/methods/ann/visitor/weight_size_visitor.hpp>
#include <mlpack/methods/ann/visitor/copy_visitor.hpp>
#include <mlpack/methods/ann/init_rules/network_init.hpp>
#include <mlpack/methods/ann/layer/layer_types.hpp>
#include <mlpack/methods/ann/init_rules/random_init.hpp>
#include <mlpack/core/optimizers/rmsprop/rmsprop.hpp>
namespace mlpack {
namespace ann /** Artificial Neural Network. */ {
/**
* Implementation of a standard feed forward network.
*
* @tparam OutputLayerType The output layer type used to evaluate the network.
* @tparam InitializationRuleType Rule used to initialize the weight matrix.
* @tparam CustomLayers Any set of custom layers that could be a part of the
* feed forward network.
*/
template<
typename OutputLayerType = NegativeLogLikelihood<>,
typename InitializationRuleType = RandomInitialization,
typename... CustomLayers
>
class MYFFN
{
public:
//! Convenience typedef for the internal model construction.
using NetworkType = MYFFN<OutputLayerType, InitializationRuleType>;
/**
* Create the MYFFN object with the given predictors and responses set (this is
* the set that is used to train the network).
* Optionally, specify which initialize rule and performance function should
* be used.
*
* If you want to pass in a parameter and discard the original parameter
* object, be sure to use std::move to avoid unnecessary copy.
*
* @param outputLayer Output layer used to evaluate the network.
* @param initializeRule Optional instantiated InitializationRule object
* for initializing the network parameter.
*/
MYFFN(OutputLayerType outputLayer = OutputLayerType(),
InitializationRuleType initializeRule = InitializationRuleType());
//! Copy constructor.
MYFFN(const MYFFN&);
//! Move constructor.
MYFFN(MYFFN&&);
//! Copy/move assignment operator.
MYFFN& operator = (MYFFN);
MYFFN(arma::mat predictors,
arma::mat responses,
OutputLayerType outputLayer = OutputLayerType(),
InitializationRuleType initializeRule = InitializationRuleType());
//! Destructor to release allocated memory.
~MYFFN();
template<typename OptimizerType>
void Train(arma::mat predictors,
arma::mat responses,
OptimizerType& optimizer);
template<typename OptimizerType = mlpack::optimization::RMSProp>
void Train(arma::mat predictors, arma::mat responses);
void Predict(arma::mat predictors, arma::mat& results);
double Evaluate(const arma::mat& parameters);
double Evaluate(const arma::mat& parameters,
const size_t begin,
const size_t batchSize,
const bool deterministic);
double Evaluate(const arma::mat& parameters,
const size_t begin,
const size_t batchSize)
{
return Evaluate(parameters, begin, batchSize, true);
}
void Gradient(const arma::mat& parameters,
const size_t begin,
arma::mat& gradient,
const size_t batchSize);
void Shuffle();
template <class LayerType, class... Args>
void Add(Args... args) { network.push_back(new LayerType(args...)); }
void Add(LayerTypes<CustomLayers...> layer) { network.push_back(layer); }
//! Return the number of separable functions (the number of predictor points).
size_t NumFunctions() const { return numFunctions; }
//! Return the initial point for the optimization.
const arma::mat& Parameters() const { return parameter; }
//! Modify the initial point for the optimization.
arma::mat& Parameters() { return parameter; }
/**
* Reset the module infomration (weights/parameters).
*/
void ResetParameters();
//! Serialize the model.
template<typename Archive>
void serialize(Archive& ar, const unsigned int /* version */);
void Forward(arma::mat inputs, arma::mat& results);
double Backward(arma::mat targets, arma::mat& gradients);
private:
void Forward(arma::mat&& input);
void ResetData(arma::mat predictors, arma::mat responses);
void Backward();
void Gradient(arma::mat&& input);
void ResetDeterministic();
/**
* Reset the gradient for all modules that implement the Gradient function.
*/
void ResetGradients(arma::mat& gradient);
/**
* Swap the content of this network with given network.
*
* @param network Desired source network.
*/
void Swap(MYFFN& network);
//! Instantiated outputlayer used to evaluate the network.
OutputLayerType outputLayer;
//! Instantiated InitializationRule object for initializing the network
//! parameter.
InitializationRuleType initializeRule;
//! The input width.
size_t width;
//! The input height.
size_t height;
//! Indicator if we already trained the model.
bool reset;
//! Locally-stored model modules.
std::vector<LayerTypes<CustomLayers...> > network;
//! The matrix of data points (predictors).
arma::mat predictors;
//! The matrix of responses to the input data points.
arma::mat responses;
//! Matrix of (trained) parameters.
arma::mat parameter;
//! The number of separable functions (the number of predictor points).
size_t numFunctions;
//! The current error for the backward pass.
arma::mat error;
//! THe current input of the forward/backward pass.
arma::mat currentInput;
//! Locally-stored delta visitor.
DeltaVisitor deltaVisitor;
//! Locally-stored output parameter visitor.
OutputParameterVisitor outputParameterVisitor;
//! Locally-stored weight size visitor.
WeightSizeVisitor weightSizeVisitor;
//! Locally-stored output width visitor.
OutputWidthVisitor outputWidthVisitor;
//! Locally-stored output height visitor.
OutputHeightVisitor outputHeightVisitor;
//! Locally-stored reset visitor.
ResetVisitor resetVisitor;
//! Locally-stored delete visitor.
DeleteVisitor deleteVisitor;
//! The current evaluation mode (training or testing).
bool deterministic;
//! Locally-stored delta object.
arma::mat delta;
//! Locally-stored input parameter object.
arma::mat inputParameter;
//! Locally-stored output parameter object.
arma::mat outputParameter;
//! Locally-stored gradient parameter.
arma::mat gradient;
//! Locally-stored copy visitor
CopyVisitor<CustomLayers...> copyVisitor;
}; // class MYFFN
} // namespace ann
} // namespace mlpack
// Include implementation.
#include "myffn_impl.hpp"
#endif



 [/quote]
比如google protobuf
[/quote]
比如google protobuf
 大神收下我的膝盖,分数全部给你!
大神能不能告诉我为什么这样就行了呢?
大神收下我的膝盖,分数全部给你!
大神能不能告诉我为什么这样就行了呢?

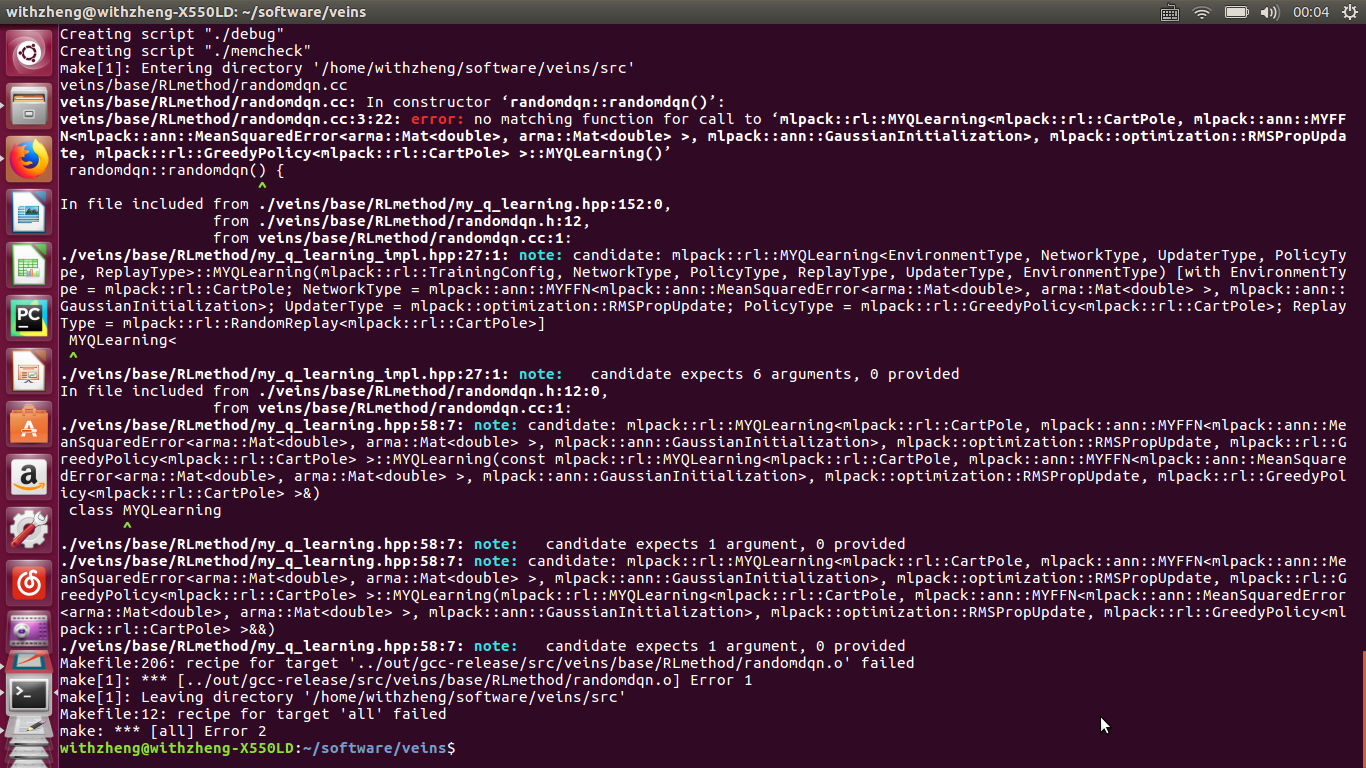
/**
* @file q_learning.hpp
* @author Shangtong Zhang
*
* This file is the definition of MYQLearning class,
* which implements Q-Learning algorithms.
*
* mlpack is free software; you may redistribute it and/or modify it under the
* terms of the 3-clause BSD license. You should have received a copy of the
* 3-clause BSD license along with mlpack. If not, see
* http://www.opensource.org/licenses/BSD-3-Clause for more information.
*/
#ifndef MLPACK_METHODS_RL_MY_Q_LEARNING_HPP
#define MLPACK_METHODS_RL_MY_Q_LEARNING_HPP
#include <mlpack/prereqs.hpp>
//#include "replay/random_replay.hpp"
//#include "training_config.hpp"
#include <mlpack/methods/reinforcement_learning/replay/random_replay.hpp>
#include <mlpack/methods/reinforcement_learning/training_config.hpp>
namespace mlpack {
namespace rl {
/**
* Implementation of various Q-Learning algorithms, such as DQN, double DQN.
*
* For more details, see the following:
* @code
* @article{Mnih2013,
* author = {Volodymyr Mnih and
* Koray Kavukcuoglu and
* David Silver and
* Alex Graves and
* Ioannis Antonoglou and
* Daan Wierstra and
* Martin A. Riedmiller},
* title = {Playing Atari with Deep Reinforcement Learning},
* journal = {CoRR},
* year = {2013},
* url = {http://arxiv.org/abs/1312.5602}
* }
* @endcode
*
* @tparam EnvironmentType The environment of the reinforcement learning task.
* @tparam NetworkType The network to compute action value.
* @tparam UpdaterType How to apply gradients when training.
* @tparam PolicyType Behavior policy of the agent.
* @tparam ReplayType Experience replay method.
*/
template <
typename EnvironmentType,
typename NetworkType,
typename UpdaterType,
typename PolicyType,
typename ReplayType = RandomReplay<EnvironmentType> >
class MYQLearning
{
public:
//! Convenient typedef for state.
using StateType = typename EnvironmentType::State;
//! Convenient typedef for action.
using ActionType = typename EnvironmentType::Action;
/**
* Create the MYQLearning object with given settings.
*
* If you want to pass in a parameter and discard the original parameter
* object, be sure to use std::move to avoid unnecessary copy.
*
* @param config Hyper-parameters for training.
* @param network The network to compute action value.
* @param policy Behavior policy of the agent.
* @param replayMethod Experience replay method.
* @param updater How to apply gradients when training.
* @param environment Reinforcement learning task.
*/
MYQLearning(TrainingConfig config,
NetworkType network,
PolicyType policy,
ReplayType replayMethod,
UpdaterType updater = UpdaterType(),
EnvironmentType environment = EnvironmentType());
/**
* Execute a step in an episode.
* @return Reward for the step.
*/
double Step();
/**
* Execute an episode.
* @return Return of the episode.
*/
double Episode();
/**
* @return Total steps from beginning.
*/
const size_t& TotalSteps() const { return totalSteps; }
//! Modify the training mode / test mode indicator.
bool& Deterministic() { return deterministic; }
//! Get the indicator of training mode / test mode.
const bool& Deterministic() const { return deterministic; }
private:
/**
* Select the best action based on given action value.
* @param actionValues Action values.
* @return Selected actions.
*/
arma::Col<size_t> BestAction(const arma::mat& actionValues);
//! Locally-stored hyper-parameters.
TrainingConfig config;
//! Locally-stored learning network.
NetworkType learningNetwork;
//! Locally-stored target network.
NetworkType targetNetwork;
//! Locally-stored updater.
UpdaterType updater;
//! Locally-stored behavior policy.
PolicyType policy;
//! Locally-stored experience method.
ReplayType replayMethod;
//! Locally-stored reinforcement learning task.
EnvironmentType environment;
//! Total steps from the beginning of the task.
size_t totalSteps;
//! Locally-stored current state of the agent.
StateType state;
//! Locally-stored flag indicating training mode or test mode.
bool deterministic;
};
} // namespace rl
} // namespace mlpack
// Include implementation
#include <veins/base/RLmethod/my_q_learning_impl.hpp>
#endif


