现在在做财务的软件,财务需求是想把销售系统所有的订单信息抽取到,所以这里我们使用了kettle工具.
看了很多前辈们写的kettle,都是先将'表输入'-->'字段选择'-->'文本输出',这里输出的是CSV的文本,最后再讲这个CSV文本导入到目标库的目标表中.
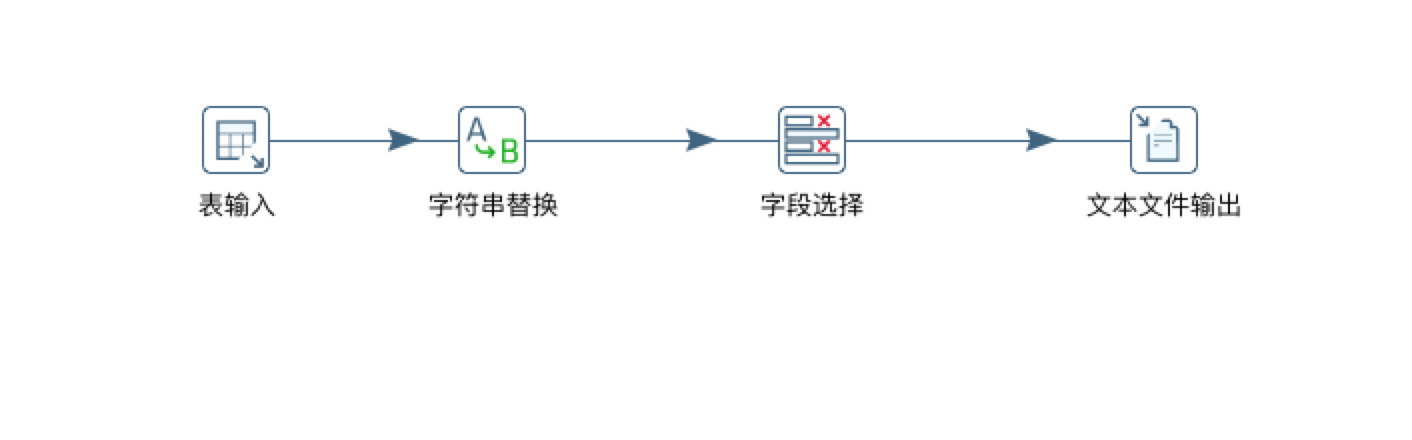
这种方式可以规避字符串不匹配的情况.
我本人使用的是更简便的方式,'表输入'-->'字段选择'-->MYSQL批量加载 的方式.
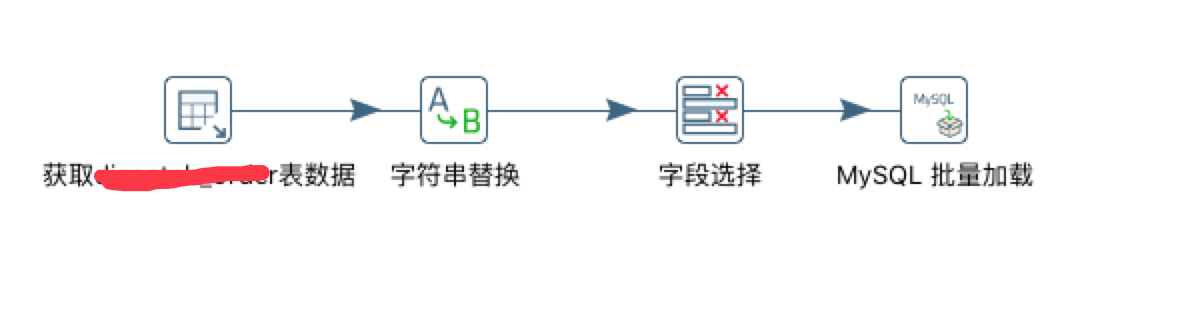
这种方式的好处是抽取完数据直接就可以添加到目标表中.但是缺点是源表的编码格式跟目标表的编码格式不同,会导致导入数据为乱码的情况.下面就是我要说的如何处理这种乱码问题.
这个问题也是从网上查了很多资料才解决的.
我是使用的linux系统启动的定时抽取的任务,所以我这里就以linux为例做说明;
Linux中,要规避中文乱码的情况要注意修改两点:
一,我们要在spoon.sh配置文件添加-Dfile.encoding=GBK参数
具体位置添加如下位置.
OPT="$OPT $PENTAHO_DI_JAVA_OPTIONS
-Dfile.encoding=GBK
-Dhttps.protocols=TLSv1,TLSv1.1,TLSv1.2
-Djava.library.path=$LIBPATH -DKETTLE_HOME=$KETTLE_HOME -DKETTLE_REPOSITORY=$KETTLE_REPOSITORY -DKETTLE_USER=$KETTLE_USER -DKETTLE_PASSWORD=$KETTLE_PASSWORD -DKETTLE_PLUGIN_PACKAGES=$KETTLE_PLUGIN_PACKAGES -DKETTLE_LOG_SIZE_LIMIT=$KETTLE_LOG_SIZE_LIMIT -DKETTLE_JNDI_ROOT=$KETTLE_JNDI_ROOT"
二,这里'表输入'要注意勾选'允许简易转换'
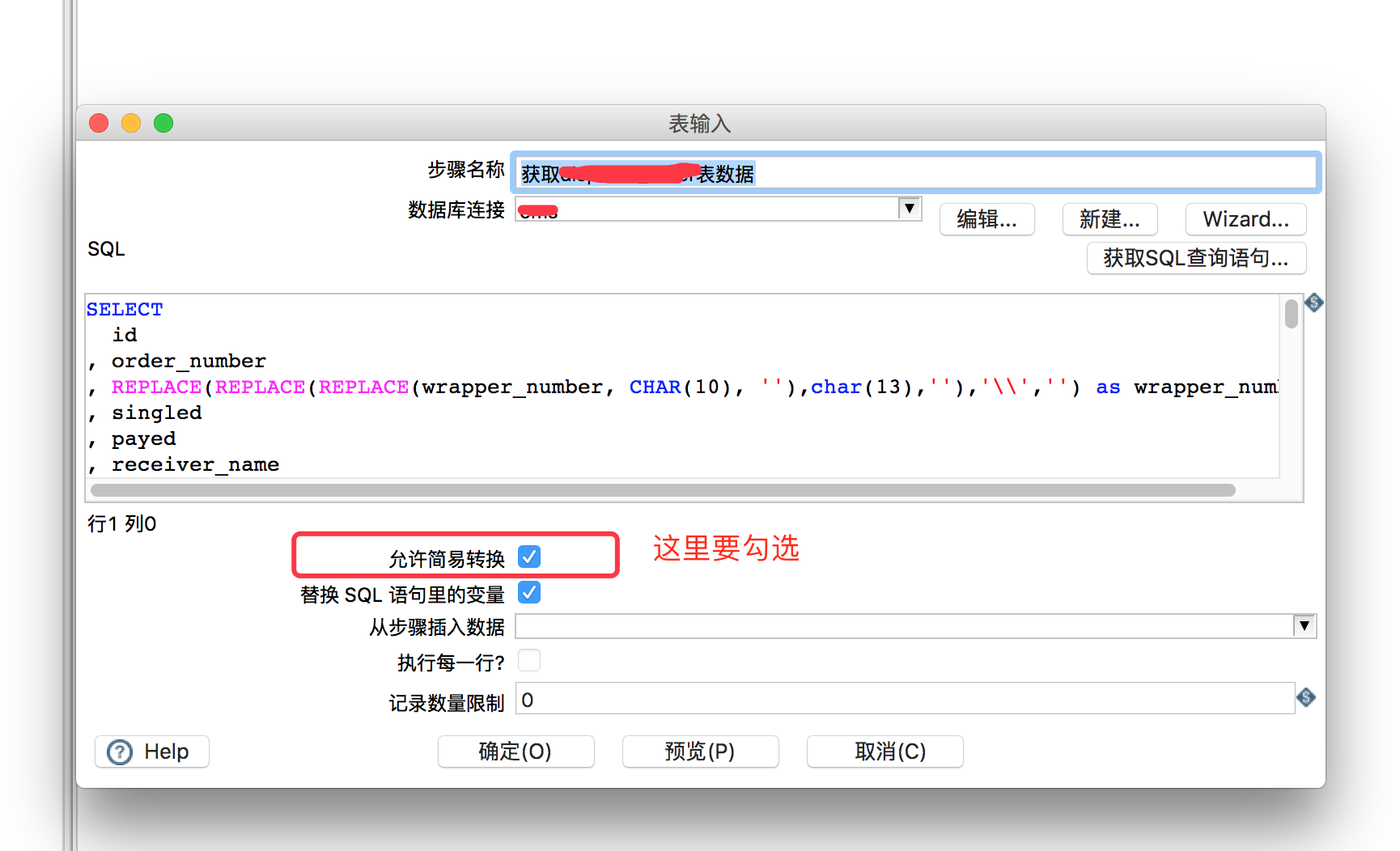
这样的话测试一下即可以避免抽取乱码的问题.
第一次发帖,写的不好大家多提意见.有问题多交流.



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
