

37,744
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享# -*- coding: utf-8 -*-
import scrapy
from vip.items import VipItem
class VipspiderSpider(scrapy.Spider):
name = 'vipspider'
allowed_domains = ['cqvip.com']
start_urls = ['http://qikan.cqvip.com/subject/article.aspx?id=983280&from=subject_subjectsearch&ls=1&page=1']
def parse(self, response):
items = []
for each in response.xpath("//div[@class='search-result-list table-list']/table/tbody/tr"):
item = VipItem()
item['title'] = each.xpath("./td[2]/a[@class='btnTitle']").extract()[0]
item['source'] = each.xpath("./td[4]").extract()[0]
item['link'] = each.xpath("./td[@class='source permissinshow']/a[@class='btnTitle btnIsView'][1]/@href").extract()[0]
print item
 我的结果也是空,有大佬能解决吗
我的结果也是空,有大佬能解决吗





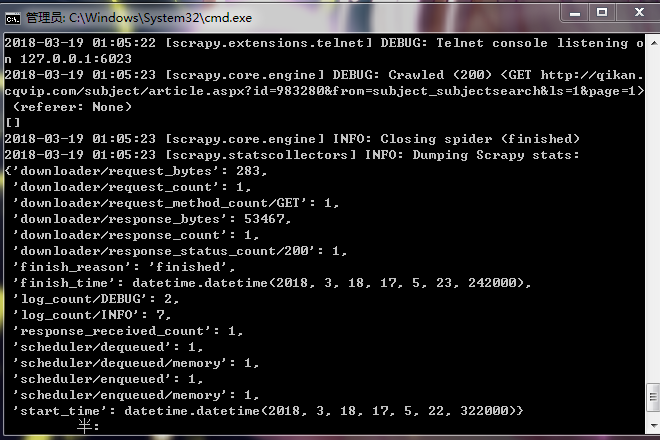 这是运行情况 输出为[]
这是运行情况 输出为[]
