社区
非技术区
帖子详情
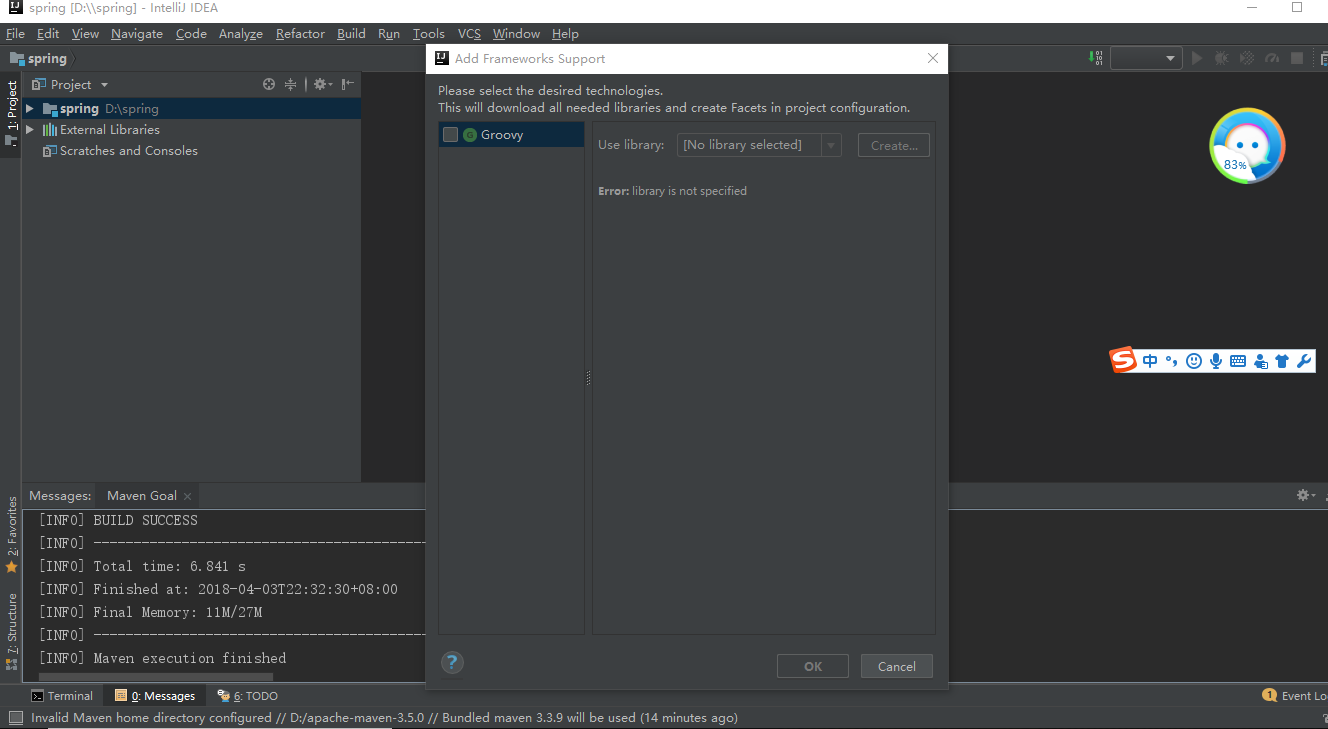
IDEA右键项目中的Add Frameworks Support没有Web Application及其他
qq_38720454
2018-04-03 11:28:11
...全文
15996
8
打赏
收藏
IDEA右键项目中的Add Frameworks Support没有Web Application及其他
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
8 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
k night
2021-05-16
打赏
举报
回复
把插件都加载试试
qq_44460207
2020-12-07
打赏
举报
回复
怎么解决呢?求告知
FromZeroToPerfect
2020-08-02
打赏
举报
回复
3
2020版本的好像是要先创建java项目,再右键选择add framework support配置,希望有点用
shyoldman
2020-04-17
打赏
举报
回复
https://blog.csdn.net/qq_37943488/article/details/105584224 可以看一下是不是这个原因
索罗斯的鸡
2019-10-03
打赏
举报
回复
楼主解决了吗?
gwd_code
2018-10-25
打赏
举报
回复
1
一样的问题。
漫天遍野都是飞虫
2018-09-03
打赏
举报
回复
嗯。。。您是怎么解决这个问题的呀,,,大佬。
MisslittleT
2018-08-07
打赏
举报
回复
1
楼主你用的是社区版的IDEA吧,社区版的好多功能都没有,还是下旗舰版的吧。
顶刊复现配电网两阶段鲁棒故障恢复研究(Matlab代码实现)
【顶刊复现】配电网两阶段鲁棒故障恢复研究(Matlab代码实现)
GBT3098.5-2025 紧固件机械性能 自攻螺钉-可搜索
GBT3098.5-2025 紧固件机械性能 自攻螺钉_可搜索.pdf
基于segmentation_models_pytorch开源模型库与自定义模型支持的大尺寸遥感影像语义分割与地物分类
项目
_使用GDAL进行栅格与矢量数据处理_通过yml配置文件.zip
基于segmentation_models_pytorch开源模型库与自定义模型支持的大尺寸遥感影像语义分割与地物分类
项目
_使用GDAL进行栅格与矢量数据处理_通过yml配置文件.zip
TypeScript类型系统与全栈
项目
ts-type-challenges(TS 类型体操标杆,条件 + 映射 + infer 全覆盖),包含 100 + 实战题:内置工具类型实现、分布式条件、自定义 DeepReadonly/DeepPartial、模板字面量类型,配套练习答案,VIP 级类型编程素材。
考虑不确定性的含集群电动汽车并网型微电网随机优化调度研究(Matlab代码实现)
考虑不确定性的含集群电动汽车并网型微电网随机优化调度研究(Matlab代码实现)
非技术区
23,404
社区成员
70,513
社区内容
发帖
与我相关
我的任务
非技术区
Java 非技术区
复制链接
扫一扫
分享
社区描述
Java 非技术区
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





