


16,472
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 char a[20] = "ש";
char sn = 0xe4;
printf("%c\n", sn);
int len = strlen(a);
printf("%d\n", len);
printf("%x %x %x %x %x %x %x", a[0], a[1], a[2], a[3], a[4], a[5], a[6]);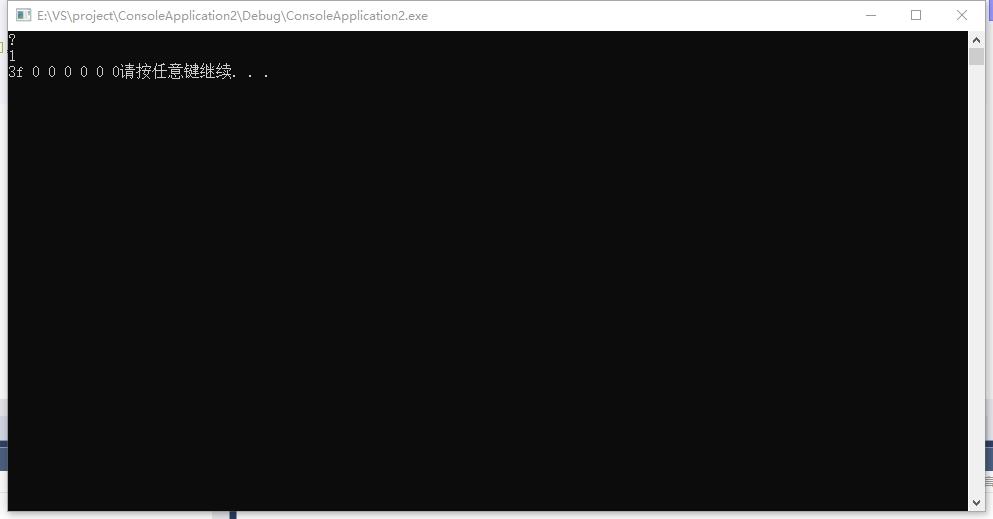

#pragma comment(lib,"user32")
#pragma comment(lib,"gdi32")
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
HWND WINAPI GetConsoleWindow();
void HideTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = FALSE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
void ShowTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = TRUE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
int main() {
HWND hwnd;
HDC hdc;
HFONT hfont;
system("color F0");
system("cls");
HideTheCursor();
hwnd = GetConsoleWindow();
hdc = GetDC(hwnd);
hfont = CreateFont(48, 0, 0, 0, 0, 0, 0, 0, 0 , 0, 0, 0, 0, "Arial Unicode MS");
SelectObject(hdc,hfont);
TextOutW(hdc,10,10,L"你好",2);
DeleteObject(hfont);
hfont = CreateFont(48, 0, 0, 0, 0, 0, 0, 0, JOHAB_CHARSET , 0, 0, 0, 0, "Arial Unicode MS");
SelectObject(hdc,hfont);
TextOutW(hdc,10,80,L"\xb7f0\xb7f0\xb2dd\xb2dd",4);
DeleteObject(hfont);
ReleaseDC(hwnd,hdc);
getch();
system("color 07");
system("cls");
ShowTheCursor();
return 0;
}


#pragma comment(lib,"user32")
#pragma comment(lib,"gdi32")
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
extern "C" HWND WINAPI GetConsoleWindow();
void HideTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = FALSE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
void ShowTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = TRUE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
int main() {
HWND hwnd;
HDC hdc;
HFONT hfont;
wchar_t wc[2];
system("color F0");
system("cls");
HideTheCursor();
hwnd = GetConsoleWindow();
hdc = GetDC(hwnd);
hfont = CreateFont(48,0,0,0,0,0,0,0,GB2312_CHARSET ,0,0,0,0,"宋体-方正超大字符集");
SelectObject(hdc,hfont);
wc[0]=0xD854u;
wc[1]=0xDC00u;
TextOutW(hdc,10,10,wc,2);
DeleteObject(hfont);
ReleaseDC(hwnd,hdc);
getch();
system("color 07");
system("cls");
ShowTheCursor();
return 0;
}
#if 0
代理项或代理项对是一对共同表示单个字符的 16 位 Unicode 编码值。需要记住的关键一点是:
代理项对实际上是 32 位单个字符,不能再假定一个 16 位 Unicode 编码值正好映射到一个字符。
使用代理项对
代理项对的第一个值是高代理项,包含介于 U+D800 到 U+DBFF 范围内的 16 位代码值。
该对的第二个值是低代理项,包含介于 U+DC00 到 U+DFFF 范围内的值。通过使用代理项对,
16 位 Unicode 编码系统可以对已由 Unicode 标准定义的一百多万个其他字符 (220) 进行寻址。
在传递给 XmlTextWriter 方法的任何字符串中都可以使用代理项字符。不过,代理项字符在编写的
XML 中应该有效。例如,万维网联合会 (W3C) 建议不允许在元素或属性的名称中使用代理项字符。
如果字符串包含无效的代理项对,则引发异常。
另外,可以使用 WriteSurrogateCharEntity 写出与代理项对相对应的字符实体。字符实体以十六
进制格式写出,并用以下公式生成:
(highChar -0xD800) * 0x400 + (lowChar -0xDC00) + 0x10000
如果字符串包含无效的代理项对,则引发异常。下面的示例显示将代理项对作为输入的 WriteSurrogateCharEntity 方法。
C#复制
// The following line writes 𐀀.
WriteSurrogateCharEntity ('\uDC00', '\uD800');
下面的示例生成一个代理项对文件,将其加载到 XmlReader 中,并用新的文件名保存文件。
然后,原始文件和新文件被加载回应用程序的 XML 文档对象模型 (DOM) 结构中以进行比较。
C#复制
char lowChar, highChar;
char [] charArray = new char[10];
FileStream targetFile = new FileStream("SurrogatePair.xml",
FileMode.Create, FileAccess.ReadWrite, FileShare.ReadWrite);
lowChar = Convert.ToChar(0xDC00);
highChar = Convert.ToChar(0xD800);
XmlTextWriter tw = new XmlTextWriter(targetFile, null);
tw.Formatting = Formatting.Indented;
tw.WriteStartElement("root");
tw.WriteStartAttribute("test", null);
tw.WriteSurrogateCharEntity(lowChar, highChar);
lowChar = Convert.ToChar(0xDC01);
highChar = Convert.ToChar(0xD801);
tw.WriteSurrogateCharEntity(lowChar, highChar);
lowChar = Convert.ToChar(0xDFFF);
highChar = Convert.ToChar(0xDBFF);
tw.WriteSurrogateCharEntity(lowChar, highChar);
// Add 10 random surrogate pairs.
// As Unicode, the high bytes are in lower
// memory; for example, word 6A21 as 21 6A.
// The high or low is in the logical sense.
Random random = new Random();
for (int i = 0; i < 10; ++i) {
lowChar = Convert.ToChar(random.Next(0xDC00, 0xE000));
highChar = Convert.ToChar(random.Next(0xD800, 0xDC00));
charArray[i] = highChar;
charArray[++i] = lowChar;
}
tw.WriteChars(charArray, 0, charArray.Length);
for (int i = 0; i < 10; ++i) {
lowChar = Convert.ToChar(random.Next(0xDC00, 0xE000));
highChar = Convert.ToChar(random.Next(0xD800, 0xDC00));
tw.WriteSurrogateCharEntity(lowChar, highChar);
}
tw.WriteEndAttribute();
tw.WriteEndElement();
tw.Flush();
tw.Close();
XmlTextReader r = new XmlTextReader("SurrogatePair.xml");
r.Read();
r.MoveToFirstAttribute();
targetFile = new FileStream("SurrogatePairFromReader.xml",
FileMode.Create, FileAccess.ReadWrite, FileShare.ReadWrite);
tw = new XmlTextWriter(targetFile, null);
tw.Formatting = Formatting.Indented;
tw.WriteStartElement("root");
tw.WriteStartAttribute("test", null);
tw.WriteString(r.Value);
tw.WriteEndAttribute();
tw.WriteEndElement();
tw.Flush();
tw.Close();
// Load both result files into the DOM and compare.
XmlDocument doc1 = new XmlDocument();
XmlDocument doc2 = new XmlDocument();
doc1.Load("SurrogatePair.xml");
doc2.Load("SurrogatePairFromReader.xml");
if (doc1.InnerXml != doc2.InnerXml) {
Console.WriteLine("Surrogate Pair test case failed");
}
在使用 WriteChars 方法(一次写出一个缓冲区的数据)写出时,输入中的代理项对可能
会在一个缓冲区内被意外拆分。由于代理项值是定义完善的,如果 WriteChars 遇到来自
较低范围或者较高范围的 Unicode 值,它将该值标识为代理项对的一半。当遇到
WriteChars 将导致从拆分代理项对的缓冲区写入的情况时,将引发异常。使用
IsHighSurrogate 方法检查缓冲区是否以高代理项字符结束。如果缓冲区中的最后一个
字符不是高代理项,可以将该缓冲区传递给 WriteChars 方法。
请参见
概念
使用 XmlTextWriter 创建格式正确的 XML
XmlTextWriter 的 XML 输出格式设置
XmlTextWriter 的命名空间功能
#endif




