这几个月在研究《基于最大似然概率的协议关键词长度确定方法》这篇论文,学习了马尔科夫,再学习了隐半马尔科夫,也去了解了报文格式,但在具体实现算法时还是遇到了很多问题,想请教下各位大牛。
问题一:文章中提到了数据状态,对于状态集,关键词的状态数是可以确定的,但是整个报文序列中所有可能的字符会有很多,那除关键词的状态外的数据状态数目应该如何确定呢?这点在论文中没能看明白。或者这里的数据状态数目是指数据字段的长度么?

问题二:在训练某一类报文时,我将每个最长频繁项与它的子集分为一组,作为一个状态的观测,但不是很能明白报文序列如何转换为,对应于隐半马尔科夫模型中的观测序列
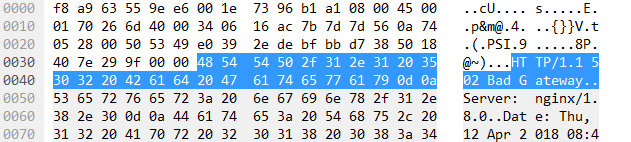
例如,在将报文转换为可输入的观测序列时,这段报文的 ‘ HT TP/1.1…… ’对应一个状态,此时对应的观测序列中的观测值应该是这一组观测集的子集中的哪一个呢。
还有就是《抗噪的未知应用层协议报文格式最佳分段方法》里有很多参数:状态最大持续长度、每个字段长度的初始概率分布中的待定参数tao 该如何设置?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

