社区
MS-SQL Server
帖子详情
left join 多条件……求指点!!!
神野惠
2018-04-19 02:17:34
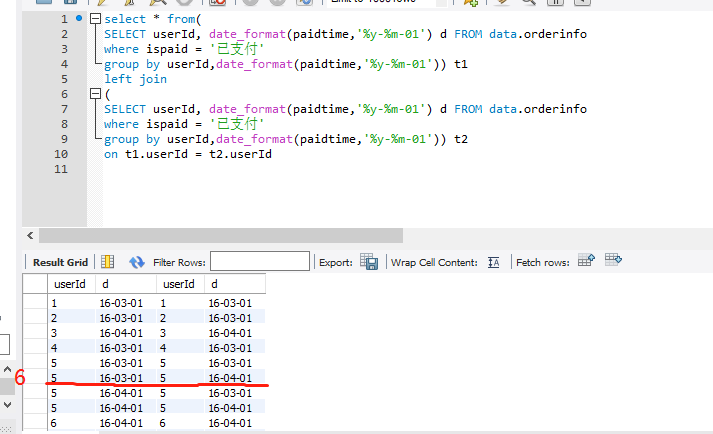
left join …on…,在on之后多加了一个条件: and t1.d = date_sub(t2.d, interval 01 month )
t2表却没有出现预期效果
下面第6行应该是条件设定后的结果,却返回了null
求解
...全文
967
4
打赏
收藏
left join 多条件……求指点!!!
left join …on…,在on之后多加了一个条件: and t1.d = date_sub(t2.d, interval 01 month ) t2表却没有出现预期效果 下面第6行应该是条件设定后的结果,却返回了null 求解
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
神野惠
2018-04-19
打赏
举报
回复
我试了,把y改为Y是可行的,感谢哈
我现在学的是很基础的,mysql,跟着老师做偶尔都会出问题 是自己电脑上的数据库
uu3131313131
2018-04-19
打赏
举报
回复
没有测试数据情况帮你分析下: 1.你确定是SQLSERVER数据库的话 date_sub是自建函数,你得看出来到底是什么作用。 这语法看着不像SQLSERVER 2.是SQLSERVER数据库 第二个关联条件改成 : t1.d=dateadd(MONTH,1,t2.d)
繁花尽流年
2018-04-19
打赏
举报
回复
LZ把'%y-%m-01'换成'%Y-%m-01'试试,实验了下'%y-%m-01'好像是有问题
二月十六
版主
2018-04-19
打赏
举报
回复
把date_sub(t2.d, interval 01 month )打印出来看看是什么值
SQL语法——
left
join
on 多
条件
本文通过实例对比了SQL中
Left
Join
On与Where的不同作用。
Left
Join
On先进行表连接匹配,Where则是在连接后进一步筛选数据。展示了不同
条件
放置位置对结果的影响。
left
join
on多
条件
深度理解
本文深入探讨了SQL左连接(
LEFT
JOIN
)的原理,强调无论何时左表数据总是完整返回。通过不同
条件
的组合,阐述了左连接在单
条件
和多
条件
下的匹配行为。当添加第二个
条件
时,可以对左表或右表进行筛选。举例说明了普通左连接、左连接结合左表筛选及右表筛选的情况,帮助读者理解左连接在实际查询中的应用。
mysql中的
left
join
用法 (及多
条件
查询
本文详细介绍了MySQL中
LEFT
JOIN
的使用方法,包括基本语法、示例以及在多
条件
查询中的应用。通过
LEFT
JOIN
可以连接多个表并获取所需数据。示例包括单
条件
和多
条件
的
LEFT
JOIN
查询,以及如何在查询中进行
条件
过滤。同时,文章还讨论了查询优化,特别是如何处理含有子查询的情况,以提高查询效率。
LEFT
JOIN
多
条件
排除第二个表中数据
本文深入解析如何使用SQL的
LEFT
JOIN
结合WHERE子句,实现从左表中排除在右表中存在的数据,包括单
条件
和多
条件
排除技巧。通过具体示例,帮助读者掌握排除法在数据库查询中的应用。
【后端百科】mysql的
join
,
left
join
,right
join
,full
join
分别是什么意思
本文详细介绍了MySQL中的四种主要
JOIN
类型,包括INNER
JOIN
、
LEFT
JOIN
、RIGHT
JOIN
和FULL OUTER
JOIN
。阐述了各类型的定义、用途、语法及示例,还对它们进行了对比分析。指出要根据具体需
求
选
JOIN
类型,且可组合
LEFT
和RIGHT
JOIN
实现FULL OUTER
JOIN
类似效果。
MS-SQL Server
34,876
社区成员
254,639
社区内容
发帖
与我相关
我的任务
MS-SQL Server
MS-SQL Server相关内容讨论专区
复制链接
扫一扫
分享
社区描述
MS-SQL Server相关内容讨论专区
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享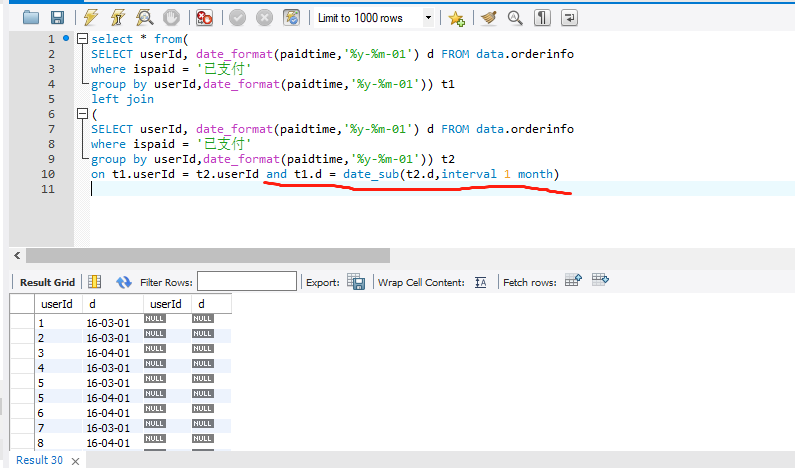

 我现在学的是很基础的,mysql,跟着老师做偶尔都会出问题
是自己电脑上的数据库
我现在学的是很基础的,mysql,跟着老师做偶尔都会出问题
是自己电脑上的数据库


