[size=18px][size=13px]python我在用selenium模拟登陆163邮箱(https://mail.163.com/)然后怎么都定位不到它的登陆id。
最后发现是用爬虫爬的数据源码和F12的数据源码不一致。
为什么会这样呢?大神能不能解释一下。
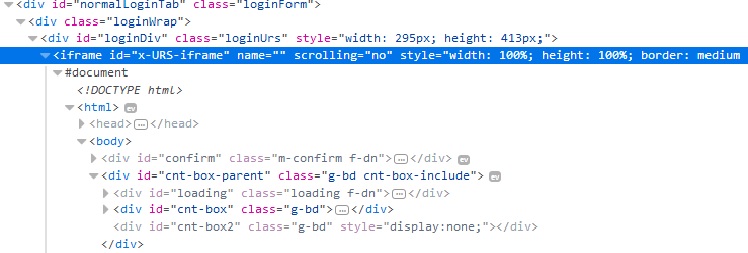

图一是我按F12显示的 id="loginDiv" 下面还有很多内容。就是登陆界面的核心。
但是爬虫爬到的源码里面<div class="loginUrs" id="loginDiv"></div> div 直接结束了。里面内容就没了。
为什么会这样,请大神给个想法,然后如果哪位大神空的化可以帮我实现一下模拟登陆然后给我借鉴吗?
求~~~~~~


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







