22,210
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
WITH cte AS (
SELECT *,
ID - ROW_NUMBER() OVER (ORDER BY TIME) AS rn
FROM AGCC
WHERE HZ > 50.03 or HZ < 50
)
SELECT *
FROM cte
WHERE rn IN (
SELECT rn
FROM cte
GROUP BY rn
HAVING DATEDIFF(SECOND, MIN(cte.TIME), MAX(TIME)) >= 15
);
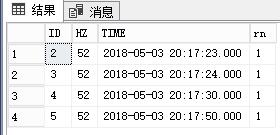
 查询后
查询后
 请问代码里的rn是什么逻辑
请问代码里的rn是什么逻辑

WITH cte AS (
SELECT *,
ID - ROW_NUMBER() OVER (ORDER BY TIME) AS rn
FROM AGCC
WHERE HZ > 50.03 or HZ < 50
)
SELECT *
FROM cte
WHERE rn IN (
SELECT rn
FROM cte
GROUP BY rn
HAVING DATEDIFF(SECOND, MIN(cte.TIME), MAX(TIME)) >= 15
);

if not object_id(N'Tempdb..#T') is null
drop table #T
Go
CREATE TABLE #T(ID INT,HZ FLOAT,TIME DATETIME)
Insert #T
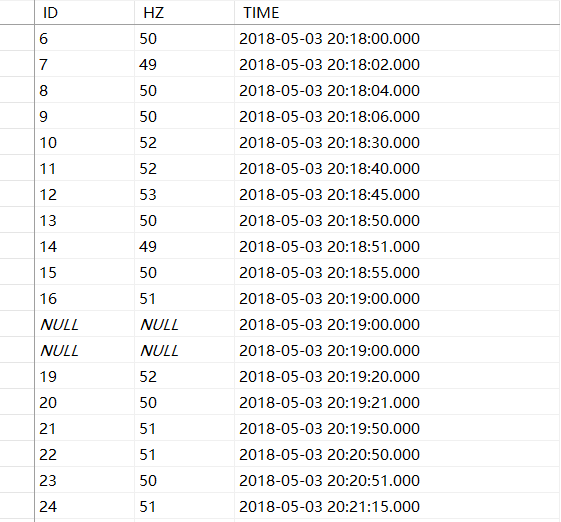
select 1,50,'2018-05-03 20:17:00.000' union all
select 2,52,'2018-05-03 20:17:23.000' union all
select 3,52,'2018-05-03 20:17:24.000' union all
select 4,50,'2018-05-03 20:17:25.000' union all
select 5,52,'2018-05-03 20:17:30.000' union all
select 6,52,'2018-05-03 20:17:50.000' union all
select 7,52,'2018-05-03 20:17:52.000' union all
select 8,52,'2018-05-03 20:17:56.000' union all
select 9,50,'2018-05-03 20:18:00.000' union all
select 10,49,'2018-05-03 20:18:02.000' union all
select 11,50,'2018-05-03 20:18:04.000'
Go
WITH CTE
AS
(SELECT *,ROW_NUMBER() OVER (PARTITION BY HZ_TYPE ORDER BY ID) AS RN
FROM
(SELECT *,CASE WHEN HZ>50.03 THEN '1' WHEN HZ<49.97 THEN 2 ELSE 0 END AS HZ_TYPE FROM #T) AS A)
SELECT *
FROM
(SELECT *,MIN(TIME) OVER (PARTITION BY HZ_TYPE,ID-RN) AS MIN_TIME,
MAX(TIME) OVER (PARTITION BY HZ_TYPE,ID-RN) AS MAX_TIME
FROM CTE
WHERE HZ_TYPE IN ('1','2')) AS A
WHERE DATEDIFF(SECOND,MIN_TIME,MAX_TIME)>15

--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
CREATE TABLE #T(ID INT,HZ FLOAT,TIME DATETIME)
Insert #T
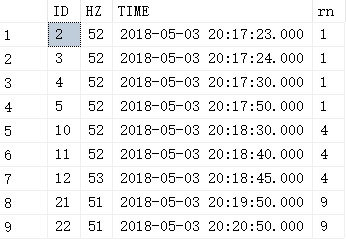
select 1,50,'2018-05-03 20:17:00.000' union all
select 2,52,'2018-05-03 20:17:23.000' union all
select 3,52,'2018-05-03 20:17:24.000' union all
select 4,52,'2018-05-03 20:17:30.000' union all
select 5,52,'2018-05-03 20:17:50.000' union all
select 6,50,'2018-05-03 20:18:00.000' union all
select 7,49,'2018-05-03 20:18:02.000' union all
select 8,50,'2018-05-03 20:18:04.000'
Go
--测试数据结束
;WITH cte AS (
SELECT *,
ID - ROW_NUMBER() OVER (ORDER BY TIME) AS rn
FROM #T
WHERE HZ > 50.03
)
SELECT *
FROM cte
WHERE rn IN (
SELECT rn
FROM cte
GROUP BY rn
HAVING DATEDIFF(SECOND, MIN(cte.TIME), MAX(TIME)) >= 15
);