22,297
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
-- 1. CTE方法
WITH CTEA
AS
(
SELECT *
FROM TABLEA AS A
INNER JOIN TABLEB AS B
ON A.ID = B.SNO
)
, CTEB
AS
(
SELECT *
, MAX(年度) OVER (PARTITION BY ID) AS 最后的年
FROM CTEA
)
SELECT *
, COUNT(*) OVER (PARTITION BY ID) AS NUM
FROM CTEA AS A
WHERE EXISTS
(
SELECT *
FROM CTEB
WHERE A.年度 = 最近年月
AND A.ID = ID
);
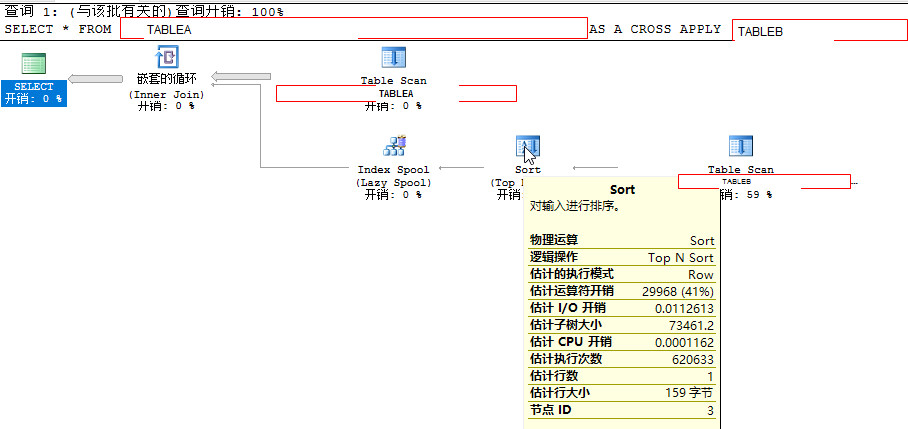
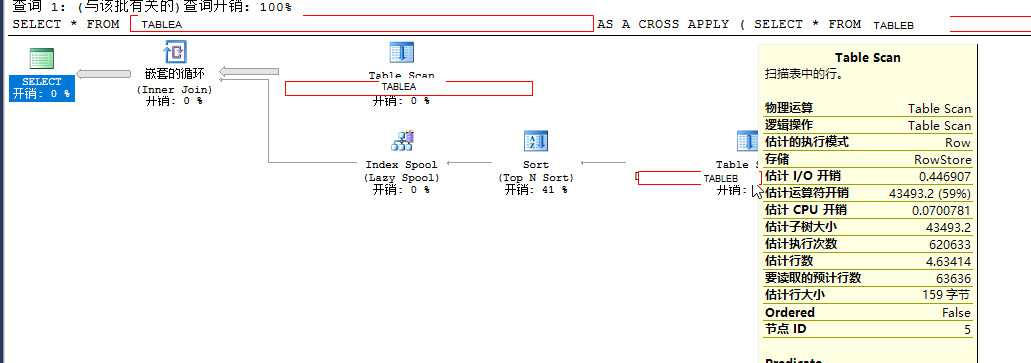
-- 2. CROSS APPLY方法
SELECT *
FROM TABLEB AS A
CROSS APPLY
(
SELECT *
FROM TABLEA
WHERE A.SNO = ID
ORDER BY
年度 DESC
OFFSET 0 ROWS FETCH NEXT 1 ROWS ONLY
) AS B




--测试数据
if not object_id(N'Tempdb..#TABLEA') is null
drop table #TABLEA
Go
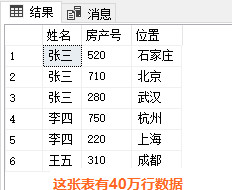
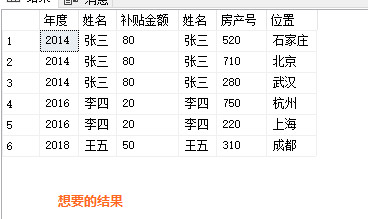
Create table #TABLEA([姓名] nvarchar(22),[房产号] int,[位置] nvarchar(23))
Insert #TABLEA
select N'张三',520,N'石家庄' union all
select N'张三',710,N'北京' union all
select N'张三',280,N'武汉' union all
select N'李四',750,N'杭州' union all
select N'李四',220,N'上海' union all
select N'王五',310,N'成都'
GO
if not object_id(N'Tempdb..#TABLEB') is null
drop table #TABLEB
Go
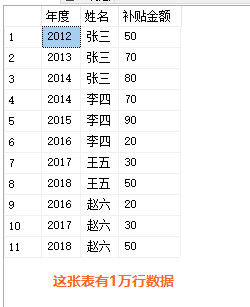
Create table #TABLEB([年度] Date,[姓名] nvarchar(22),[补贴金额] int)
Insert #TABLEB
select '2012',N'张三',50 union all
select '2013',N'张三',70 union all
select '2014',N'张三',80 union all
select '2014',N'李四',70 union all
select '2015',N'李四',90 union all
select '2016',N'李四',20 union all
select '2017',N'王五',30 union all
select '2018',N'王五',50 union all
select '2016',N'赵六',20 union all
select '2017',N'赵六',30 union all
select '2018',N'赵六',50
Go
--测试数据结束
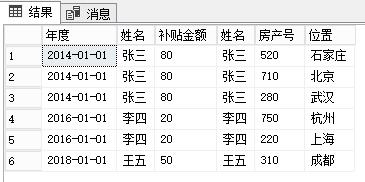
SELECT t.年度,
t.姓名,
t.补贴金额,
#TABLEA.*
FROM #TABLEA
LEFT JOIN
(
SELECT *,
ROW_NUMBER() OVER (PARTITION BY 姓名 ORDER BY 年度 DESC) rn
FROM #TABLEB
) t
ON t.姓名 = #TABLEA.姓名
AND t.rn = 1;