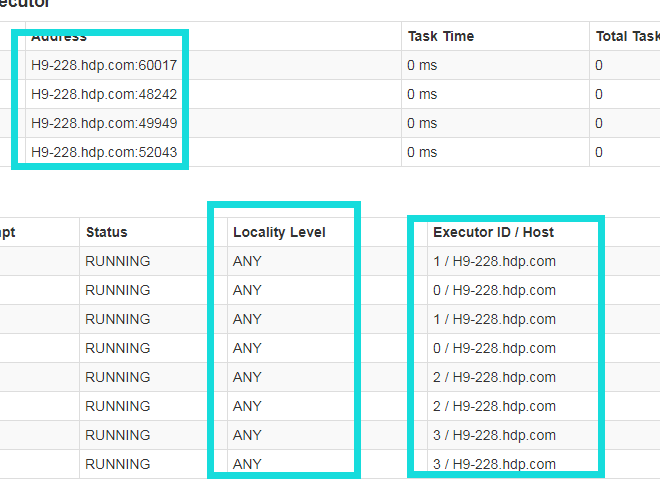
楼主好,我也遇到了这个问题,所有的job都集中到了一台机器上算,但是数据是在多台机器上的。请问楼主怎么解决了。
[quote=引用 2 楼 trnanan 的回复:] [quote=引用 1 楼 link0007 的回复:] 是你数据都来自于这台机吧?你可以尝试reparation后cache。然后在cache后的rdd/dataset上进行后续操作
[quote=引用 1 楼 link0007 的回复:] 是你数据都来自于这台机吧?你可以尝试reparation后cache。然后在cache后的rdd/dataset上进行后续操作
是你数据都来自于这台机吧?你可以尝试reparation后cache。然后在cache后的rdd/dataset上进行后续操作
1,258
社区成员
1,168
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享