


27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






 declare @tablename varchar(200)
declare @index_Id int
declare @sqlstatement nvarchar(max)
declare @databasename varchar(200) ='home'
declare cur_tables cursor
for (select schema_name(schema_id) +'.'+name as tableName
from sys.tables )
open cur_tables
fetch next from cur_tables into @tablename
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;
create table #tempTabIndall(PageFID bigint, PagePID bigint, IAMFID bigint, IAMPID bigint, ObjectID bigint, IndexId bigint, PartitionNumber bigint, PartitionID bigint,
iam_chain_type varchar(500) , PageType bigint, IndexLevel bigint, NextPageFID bigint, NextPagePID bigint,PrevPageFID bigint, PrevPagePID bigint)
create index idx_pagefid on #tempTabIndall(PageFID) ;
while @@FETCH_STATUS = 0
begin
declare cur_indexes cursor for
(select index_id from sys.indexes where object_id = object_id(@tablename))
open cur_indexes
fetch next from cur_indexes into @index_Id
while @@FETCH_STATUS = 0
begin
set @sqlstatement = N'insert into #tempTabIndall
exec sp_executesql N''DBCC IND(' + @databasename + ','''''+@tablename+''''',' + convert(varchar(max),@index_Id)+')''' ;
print @sqlstatement
exec sp_executesql @sqlstatement
fetch next from cur_indexes into @index_Id
end
close cur_indexes
deallocate cur_indexes
fetch next from cur_tables into @tablename
end
close cur_tables
deallocate cur_tables
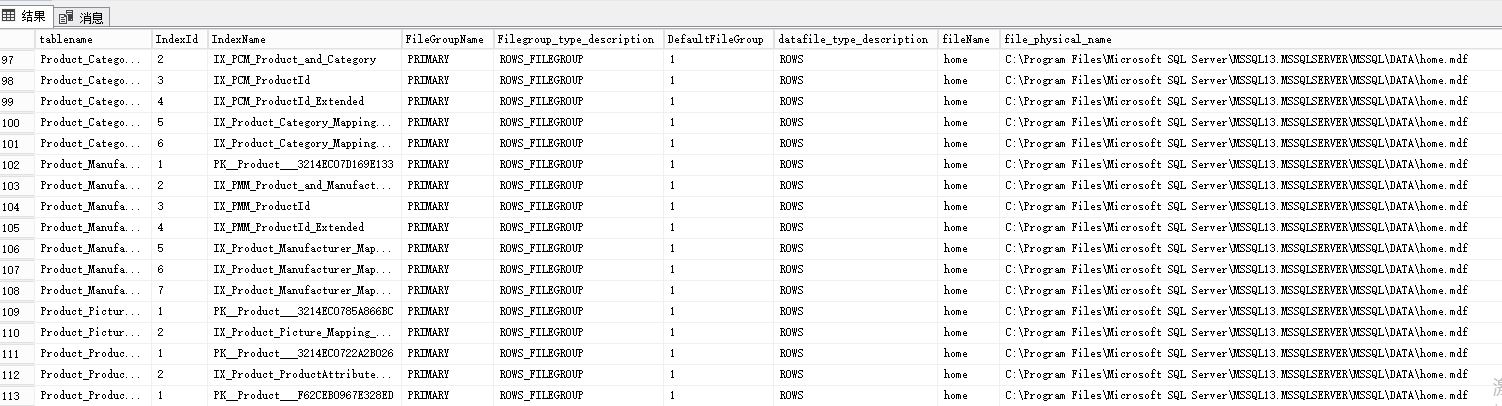
select distinct
object_name(t.ObjectID) as tablename
, t.IndexId
, ti.name as IndexName
, f.FileGroupName
, f.Filegroup_type_description
, f.DefaultFileGroup
, f.datafile_type_description
, f.fileName
, f.file_physical_name
from #tempTabIndall t
inner join (select distinct object_id,index_id,name from sys.indexes) ti on t.ObjectID = ti.object_id and t.IndexId = ti.index_id
left join (
select
isnull(data_file_id,0 ) as data_file_id
, isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select
file_id as data_file_id
,type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
)f on f.data_file_id = t.PageFID
order by f.file_physical_name asc ,object_name(t.ObjectID) asc, t.IndexId asc
如果你怀疑是 SSD 上的数据文件中存储的表,因为缺乏索引而变慢,那么只要筛选 file_physical_name 是你所用 SSD 盘路径,取其中一表,查看其或者依赖它的存储过程 的执行计划就可以。
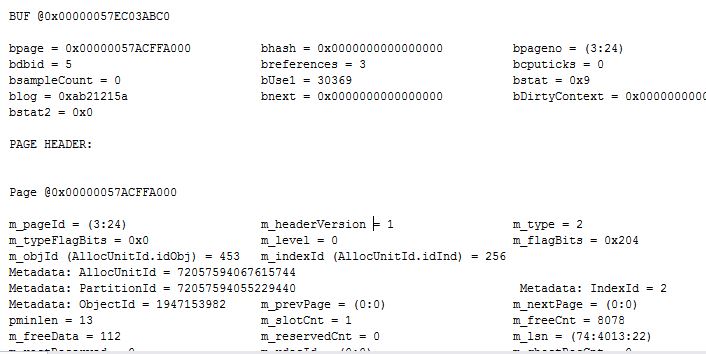
我曾经写过一篇比较啰嗦的文章 , 用来分析 SQL Server 的内部存储结构,你有兴趣可以参考 :
https://blog.csdn.net/wujiandao/article/details/51501522
第二个问题,是你的查询变慢了
这就需要你来配合 :
1 慢的 SQL ,其 SQL 语句及执行计划是不是可以贴一下 ?
2 在并发没有明显加大的情况 下 ,SQL 变慢可以通过 set profile time/IO 等方式 查询具体指标 ,比如解析慢了,还是 IO 慢了
3 如果是查询多次之后 ,查询区域稳定,那么就是执行计划以及数据缓存重新抽取造成的,不必惊慌
我同样也写过 性能分析的文章 ,不怕啰嗦的话也可以读一读
https://blog.csdn.net/wujiandao/article/details/51307741
其实,前面几位答主说的很对了,最快的方式就是直接重建索引,看看是否有效 !
[/quote]
多谢多谢;
我的方式是: 先分离数据库;然后移动数据文件到 SSD; 然后 附加数据库;
这样看来, 索引是 应该重建的吧 ?
declare @tablename varchar(200)
declare @index_Id int
declare @sqlstatement nvarchar(max)
declare @databasename varchar(200) ='home'
declare cur_tables cursor
for (select schema_name(schema_id) +'.'+name as tableName
from sys.tables )
open cur_tables
fetch next from cur_tables into @tablename
if exists( select 1 from tempdb.sys.tables where upper(name) like upper('%tempTabIndall%') )
drop table #tempTabIndall ;
create table #tempTabIndall(PageFID bigint, PagePID bigint, IAMFID bigint, IAMPID bigint, ObjectID bigint, IndexId bigint, PartitionNumber bigint, PartitionID bigint,
iam_chain_type varchar(500) , PageType bigint, IndexLevel bigint, NextPageFID bigint, NextPagePID bigint,PrevPageFID bigint, PrevPagePID bigint)
create index idx_pagefid on #tempTabIndall(PageFID) ;
while @@FETCH_STATUS = 0
begin
declare cur_indexes cursor for
(select index_id from sys.indexes where object_id = object_id(@tablename))
open cur_indexes
fetch next from cur_indexes into @index_Id
while @@FETCH_STATUS = 0
begin
set @sqlstatement = N'insert into #tempTabIndall
exec sp_executesql N''DBCC IND(' + @databasename + ','''''+@tablename+''''',' + convert(varchar(max),@index_Id)+')''' ;
print @sqlstatement
exec sp_executesql @sqlstatement
fetch next from cur_indexes into @index_Id
end
close cur_indexes
deallocate cur_indexes
fetch next from cur_tables into @tablename
end
close cur_tables
deallocate cur_tables
select distinct
object_name(t.ObjectID) as tablename
, t.IndexId
, ti.name as IndexName
, f.FileGroupName
, f.Filegroup_type_description
, f.DefaultFileGroup
, f.datafile_type_description
, f.fileName
, f.file_physical_name
from #tempTabIndall t
inner join (select distinct object_id,index_id,name from sys.indexes) ti on t.ObjectID = ti.object_id and t.IndexId = ti.index_id
left join (
select
isnull(data_file_id,0 ) as data_file_id
, isnull(g.FileGroupName,'LOG File Group') as FileGroupName
, isnull(g.type_desc,'LOG FILE GROUP') as Filegroup_type_description
, isnull(g.is_default,0) as DefaultFileGroup
, f.type_desc as datafile_type_description
, f.name as fileName
, f.physical_name as file_physical_name
, f.state_desc as datafilestatus
, f.size_mb as datafile_size_mb
, f.max_size_mb as datafile_max_size_mb
from (
select name as FileGroupName
,data_space_id
,type_desc
,is_default
from sys.filegroups
) g
right outer join (
select
file_id as data_file_id
,type_desc
,data_space_id
,name
,physical_name
,state_desc
,size * 8 /1024 as size_mb
,max_size * 8 /1024 as max_size_mb
from sys.database_files
) f on g.data_space_id = f.data_space_id
)f on f.data_file_id = t.PageFID
order by f.file_physical_name asc ,object_name(t.ObjectID) asc, t.IndexId asc
如果你怀疑是 SSD 上的数据文件中存储的表,因为缺乏索引而变慢,那么只要筛选 file_physical_name 是你所用 SSD 盘路径,取其中一表,查看其或者依赖它的存储过程 的执行计划就可以。
我曾经写过一篇比较啰嗦的文章 , 用来分析 SQL Server 的内部存储结构,你有兴趣可以参考 :
https://blog.csdn.net/wujiandao/article/details/51501522
第二个问题,是你的查询变慢了
这就需要你来配合 :
1 慢的 SQL ,其 SQL 语句及执行计划是不是可以贴一下 ?
2 在并发没有明显加大的情况 下 ,SQL 变慢可以通过 set profile time/IO 等方式 查询具体指标 ,比如解析慢了,还是 IO 慢了
3 如果是查询多次之后 ,查询区域稳定,那么就是执行计划以及数据缓存重新抽取造成的,不必惊慌
我同样也写过 性能分析的文章 ,不怕啰嗦的话也可以读一读
https://blog.csdn.net/wujiandao/article/details/51307741
其实,前面几位答主说的很对了,最快的方式就是直接重建索引,看看是否有效 !
[/quote]
多谢多谢;
我的方式是: 先分离数据库;然后移动数据文件到 SSD; 然后 附加数据库;
这样看来, 索引是 应该重建的吧 ?


