社区
MS-SQL Server
帖子详情
with drop_existing 重建了聚集索引后,还需要手动重建每一个非聚集索引吗?
samyp1234
2018-06-06 02:24:59
sqlserver2008;一个表,有聚集索引、和非聚集索引;
现在想重建全部索引;
先执行类似这个SQL,进行了聚集索引的重建,
create unique clustered index PK_1 on t1(id ) with ( drop_existing=on) ,
我的问题是: 这个SQL,会自动重建全部的 非聚集索引吗?还是需要 我再手动重建每一个 非聚集索引呢 ?
...全文
1404
7
打赏
收藏
with drop_existing 重建了聚集索引后,还需要手动重建每一个非聚集索引吗?
sqlserver2008;一个表,有聚集索引、和非聚集索引; 现在想重建全部索引; 先执行类似这个SQL,进行了聚集索引的重建, create unique clustered index PK_1 on t1(id ) with ( drop_existing=on) , 我的问题是: 这个SQL,会自动重建全部的 非聚集索引吗?还是需要 我再手动重建每一个 非聚集索引呢 ?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
7 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
samyp1234
2018-06-09
打赏
举报
回复
引用 6 楼 yenange 的回复:
with drop_existing 重建了聚集索引后, 不手动去重建非聚集索引,那么,非聚集索引 还能正常使用吗? 简单来说,就是 原来 走非聚集索引的 SQL,现在还是正常走非聚集索引吗 ? 不需要重建非聚集索引,只要它们还能正常工作 就行;
吉普赛的歌
版主
2018-06-08
打赏
举报
回复
薛定谔的DBA
2018-06-08
打赏
举报
回复
非聚集索引不会重建,统计信息也不会更新,与 rebuild 索引一样。 只有直接删除聚集索引,再创建聚集索引,非聚集索引才自动跟踪重建。
dbLenis
2018-06-07
打赏
举报
回复
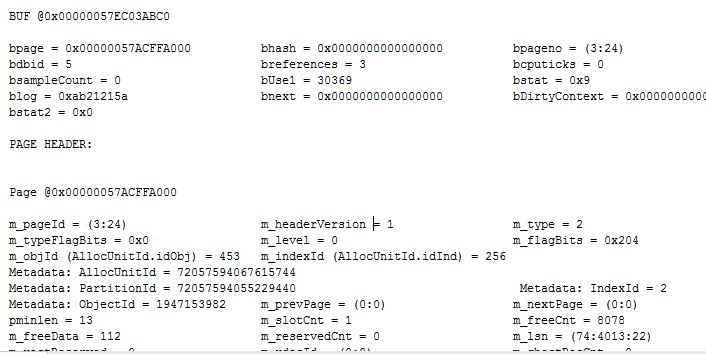
肯定的回答你,会重建所有非聚集索引。
下面是证明:
1) 找到该表的所有索引
2 ) 在没有重建聚集索引之前,分析非聚集索引的存储结构,并保存
3) 在重建完聚集索引之后,重复第2)步,分析索引的存储结构
1) 找到该表的所有索引:将红色字体部分替换为你的表
select * from sys.indexes where object_id = object_id
(N'dbo.homehistory')
2)在没有重建聚集索引之前,分析非聚集索引的存储结构,并保存
dbcc ind(home,'
dbo.homehistory
',0)
dbcc ind(home,
'dbo.homehistory
',2)
如果有其他非聚集索引,按照 index_id 来替换上述命令中的0和2,即可查看该索引的存储结构
这里的 m_pageId = (3:24) 就是原先没有重建聚集索引之前的数据页,而重建之后,这个页码有变化,请仔细对比
写过一篇啰嗦的文章,讲内部存储,有兴趣不妨一看
https://blog.csdn.net/wujiandao/article/details/51501522
samyp1234
2018-06-07
打赏
举报
回复
没人知道吗 ?
samyp1234
2018-06-07
打赏
举报
回复
with drop_existing 重建了聚集索引后, 对于非聚集索引,如果不重建非聚集索引,还能正常使用吗?
卖水果的net
版主
2018-06-06
打赏
举报
回复
一个一个来。
SQL Server 2000数据库中如何
重建
索引
在SQL Server 2000中,如果要用
一个
步骤重新创建索引,而不想删除旧索引并重新创建同一索引,则使用CREATE INDEX语句的
DROP
_
EXIS
TING
子句可以提高效率。这一优点既适用于
聚集索引
也适用于非
聚集索引
。以删除旧索引然后重新创建同一索引的方式
重建
聚集索引
,是一种昂贵的方法,因为所有二级索引都使用聚集键指向数据行。如果只是删除
聚集索引
然后重新创建,则会使所有非
聚集索引
都被删除和重新创建两次。一旦删除
聚集索引
并再次
重建
该索引,就会发生这种情形。通过在
一个
步骤中重新创建索引,可以避免这一昂贵的做法。
对SQL Server索引的探讨.pdf
对SQL Server索引的探讨.pdf
数据库 创建索引 sql oracle
1.索引的创建与使用 2.创建索引的原则 3.索引的分类 4.创建索引的多种方法 5.管理索引 6.索引优化 7.查看、修改索引属性 8.修改索引名 9.删除索引
SQLServer教程第8章索引的创建与维护[参考].pdf
SQLServer教程第8章索引的创建与维护[参考].pdf
SQL Server索引技术的教学实践.pdf
SQL Server索引技术的教学实践.pdf
MS-SQL Server
34,874
社区成员
254,640
社区内容
发帖
与我相关
我的任务
MS-SQL Server
MS-SQL Server相关内容讨论专区
复制链接
扫一扫
分享
社区描述
MS-SQL Server相关内容讨论专区
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享