代码如下:
MERGE INTO T_PA_CITEM_KIND t_pa
USING CCIC.PRPCITEMKIND t_p
ON (t_pa.POLICYNO = t_p.POLICYNO
AND t_pa.SEQNO = t_p.ITEMKINDNO )
WHEN MATCHED THEN
UPDATE
SET t_pa.RISKCODE = t_p.RISKCODE
, t_pa.CLAUSENAME = t_p.KINDNAME
, t_pa.KINDNAME = t_p.ItemDetailName
, t_pa.STARTDATE = t_p.STARTDATE
, t_pa.STARTHOUR = t_p.STARTHOUR
, t_pa.ENDDATE = t_p.ENDDATE
, t_pa.ENDHOUR = t_p.ENDHOUR
, t_pa.CURRENCY = t_p.CURRENCY
, t_pa.CALCULATEFLAG = t_p.CALCULATEFLAG
, t_pa.UNITAMOUNT = t_p.UNITAMOUNT
, t_pa.QUANTITY = t_p.QUANTITY
, t_pa.RATE = t_p.RATE
, t_pa.SHORTRATE = t_p.SHORTRATE
, t_pa.SHORTRATEFLAG = t_p.SHORTRATEFLAG
, t_pa.AMOUNT = t_p.AMOUNT
, t_pa.PREMIUM = t_p.PREMIUM
, t_pa.KINDVAT = t_p.KINDVAT
, t_pa.TNIPREMIUM = t_p.TNIPREMIUM
, t_pa.VATRATETYPE = t_p.VATRATETYPE
, t_pa.FLAG = t_p.FLAG
WHEN NOT MATCHED THEN
INSERT (POLICYNO, SEQNO, ITEMTYPE, REL_REF_SEQNO, RISKCODE, CLAUSECODE, CLAUSENAME, KINDCODE
, KINDNAME, STARTDATE, STARTHOUR, ENDDATE, ENDHOUR, CURRENCY, CALCULATEFLAG, UNITAMOUNT
, UNITPREMIUM, QUANTITY, RATE, SHORTRATE, SHORTRATEFLAG, AMOUNT, PREMIUM, KINDVAT
, TNIPREMIUM, VATRATETYPE, FLAG, ORIGININPUTFLAG)
VALUES( t_p.POLICYNO
, t_p.ITEMKINDNO
, NULL
, NULL
, t_p.RISKCODE
, null
, t_p.KINDNAME
, null
, t_p.ItemDetailName
, t_p.STARTDATE
, t_p.STARTHOUR
, t_p.ENDDATE
, t_p.ENDHOUR
, t_p.CURRENCY
, t_p.CALCULATEFLAG
, t_p.UNITAMOUNT
, NULL
, t_p.QUANTITY
, t_p.RATE
, t_p.SHORTRATE
, t_p.SHORTRATEFLAG
, t_p.AMOUNT
, t_p.PREMIUM
, t_p.KINDVAT
, t_p.TNIPREMIUM
, t_p.VATRATETYPE
, t_p.FLAG
, 'Y'
)
执行计划如下:
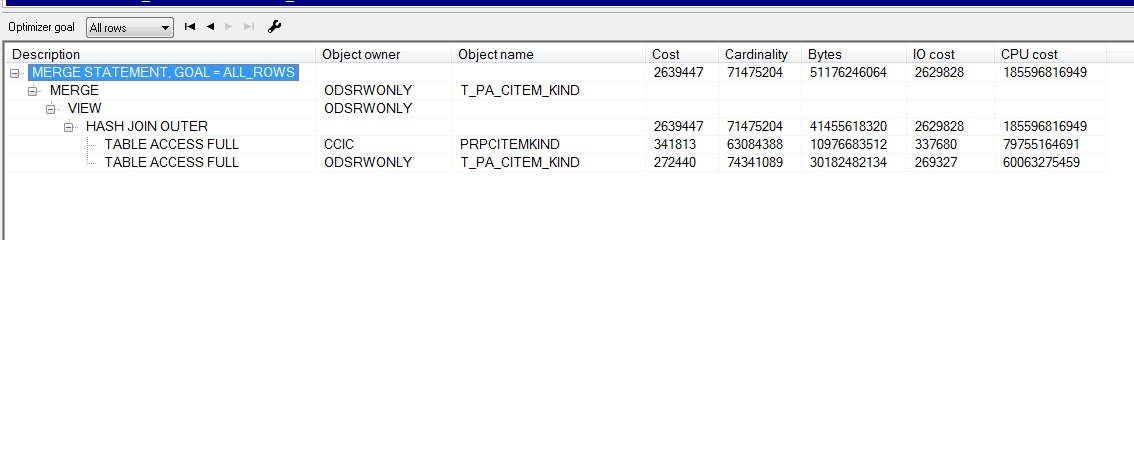
这两个表数据量都是4千万以上的。更新和插入的数据量都挺大的。实际执行过程还有一个时间标志,目前没有,所以没加。
执行时间太长,请问有什么优化的办法。两个都有主键,关联也是用主键关联的。
在线等,谢谢!



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





