


20,842
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
-- Create table
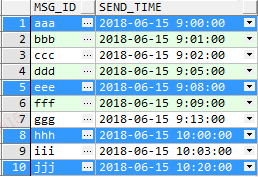
create table TEST
(
msg_id VARCHAR2(200),
send_time DATE
)
insert into test (MSG_ID, SEND_TIME)
values ('aaa', to_date('15-06-2018 09:00:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('bbb', to_date('15-06-2018 09:01:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('ccc', to_date('15-06-2018 09:02:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('ddd', to_date('15-06-2018 09:05:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('eee', to_date('15-06-2018 09:08:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('fff', to_date('15-06-2018 09:09:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('ggg', to_date('15-06-2018 09:13:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('hhh', to_date('15-06-2018 10:00:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('iii', to_date('15-06-2018 10:03:00', 'dd-mm-yyyy hh24:mi:ss'));
insert into test (MSG_ID, SEND_TIME)
values ('jjj', to_date('15-06-2018 10:20:00', 'dd-mm-yyyy hh24:mi:ss'));

WITH t AS
(SELECT row_number() over(ORDER BY send_time) rn, msg_id, send_time
FROM TEST),
tmp(rn,
msg_id,
send_time,
flag_time) AS
(SELECT rn, msg_id, send_time, send_time
FROM t
WHERE rn = 1
UNION ALL
SELECT t.rn
,t.msg_id
,t.send_time
,CASE
WHEN t.send_time <= tmp.flag_time + 1 / 1440 * 5 THEN
tmp.flag_time
ELSE
t.send_time
END
FROM tmp, t
WHERE t.rn = tmp.rn + 1),
t2 AS
(SELECT msg_id
,send_time
,flag_time
,row_number() over(PARTITION BY flag_time ORDER BY send_time) f
FROM tmp)
SELECT msg_id, send_time FROM t2 WHERE f = 1;
with a as
(select msg_id, a_time, b_time
from (select a.msg_id,
a.send_time a_time,
b.send_time b_time,
row_number() over(partition by a.rowid order by b.send_time) rn
from test a
left join test b
on b.send_time > a.send_time + 1 / 24 / 60 * 5)
where rn = 1)
select msg_id,a_time
from a
start with a.msg_id = 'aaa'
connect by a_time = prior b_time

