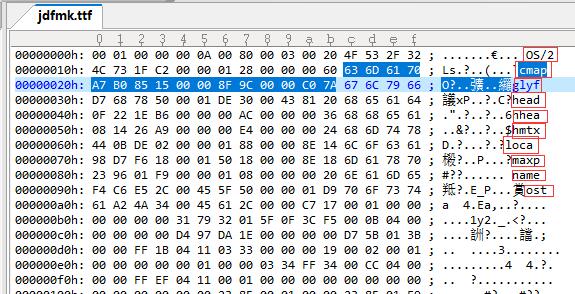
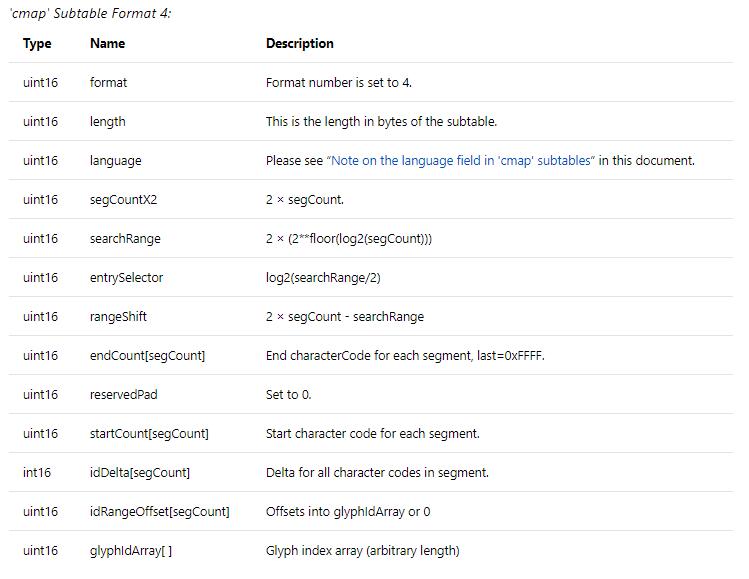
如何从Unicode获取字体文件中的映射关系
对于给定的系统字库(可以通过注册表获取对应的文件名称),给定一个系统字库名和一个Unicode代码(包括4字节CJK-B/C/D/E/F区的汉字),需要解决:
1. 字库是否存在;
2. 该字库存在的风格(Bold, Italic等等);
3. 该字符在字库文件中是否存在(Regular或Reguaular不存在则Bold,其中一种即可);
4. 字符存在时字形(Glyph)数据是否存在(非空白);
5. 字形存在时获取该字形对应的所有Unicode编码(一个字形可以对应多个Unicode编码)。
前面4项目前是可以通过API做到的,最后一项找不到头绪,请大侠帮忙,可以有偿获取源码(请加QQ商议),但需要将上面所有内容封装到一个VB类,如能同时提供VB.NET(2005或2008)可用则更好。
QQ: 616139, 请备注。


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



 [/quote]
[/quote]