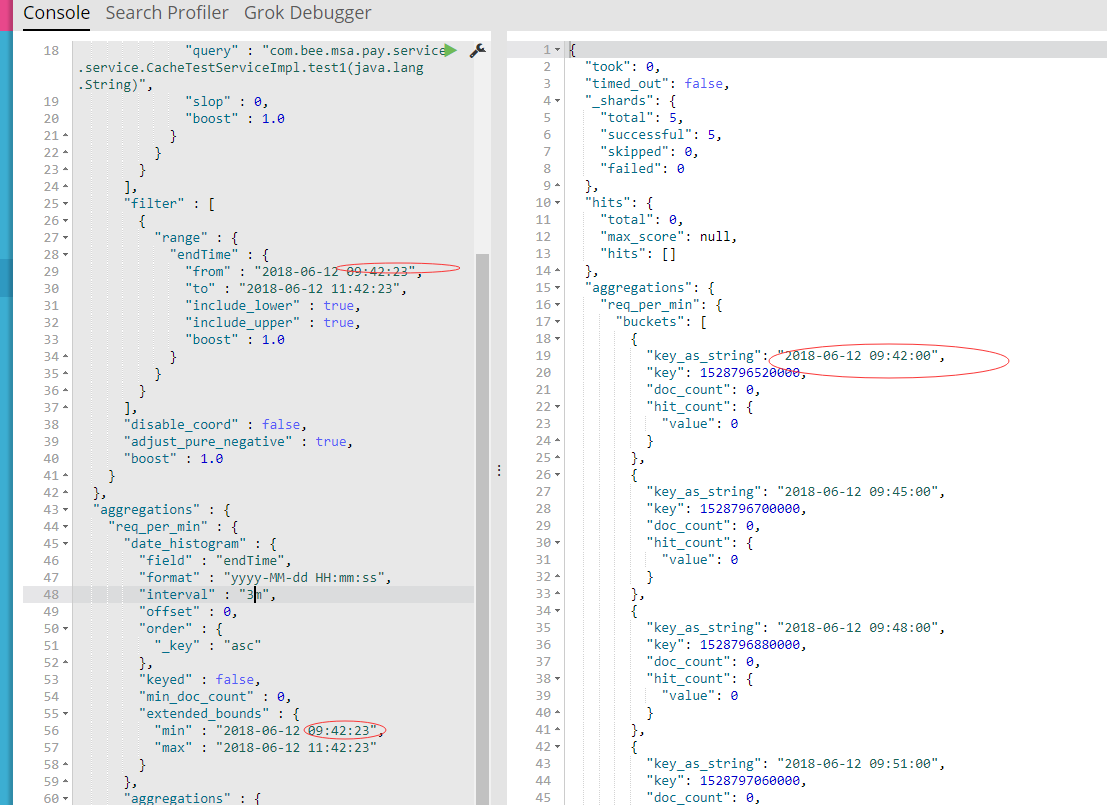
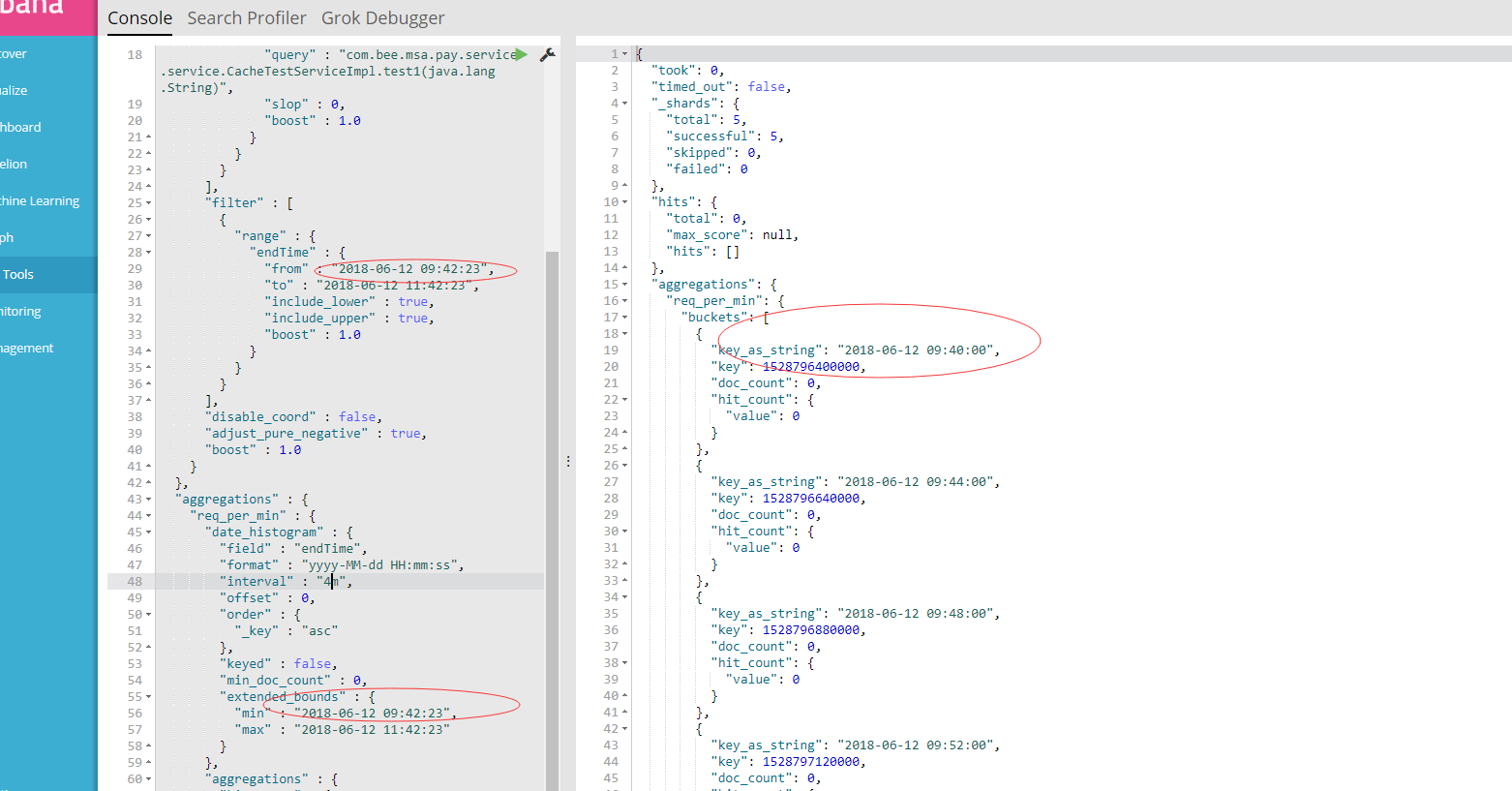
大佬 请问你的问题解决了吗 我 查询当天的 数据 按两个小时统计一次 本应该从 00点到 24点 但是 他从前一天的 16点开始查询 一直到 第二天的 4点。。。但是 数据是对的 除了多了几个点。。。这个应该怎么解决。。
计算es桶聚合bucket_key的公式是 bucket_key = Math.floor((value - offset) / interval) * interval + offset 结束时间往前偏移了可能是少掉的时间段里面没有数据。
少掉这段时间没有数据,强制返回空桶,也应该有个空桶啊。
value代表的是什么啊。偏移量那个我到知道
51,411
社区成员
86,028
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





