


27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
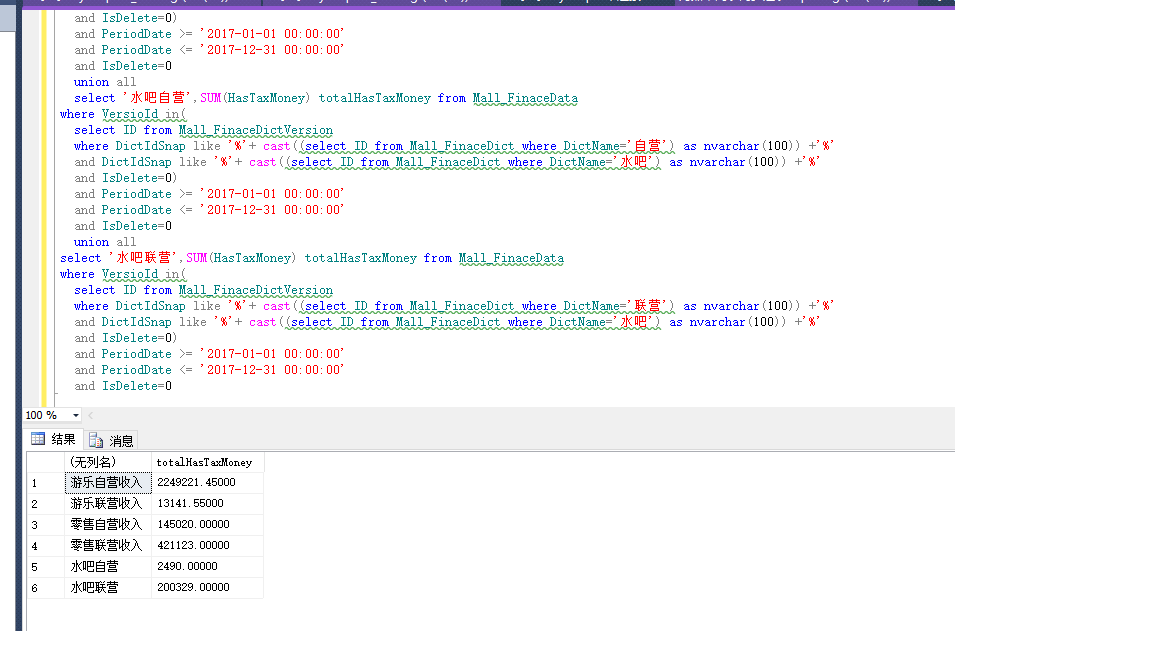
select '零售自营收入',SUM(HasTaxMoney) totalHasTaxMoney from Mall_FinaceData
where VersioId in(
select ID from Mall_FinaceDictVersion
where DictIdSnap like '%'+ cast((select ID from Mall_FinaceDict where DictName='自营') as nvarchar(100)) +'%'
and DictIdSnap like '%'+ cast((select ID from Mall_FinaceDict where DictName='零售') as nvarchar(100)) +'%'
)
union all
select '零售联营收入',SUM(HasTaxMoney) totalHasTaxMoney from Mall_FinaceData
where VersioId in(
select ID from Mall_FinaceDictVersion
where DictIdSnap like '%'+ cast((select ID from Mall_FinaceDict where DictName='联营') as nvarchar(100)) +'%'
and DictIdSnap like '%'+ cast((select ID from Mall_FinaceDict where DictName='零售') as nvarchar(100)) +'%'
)

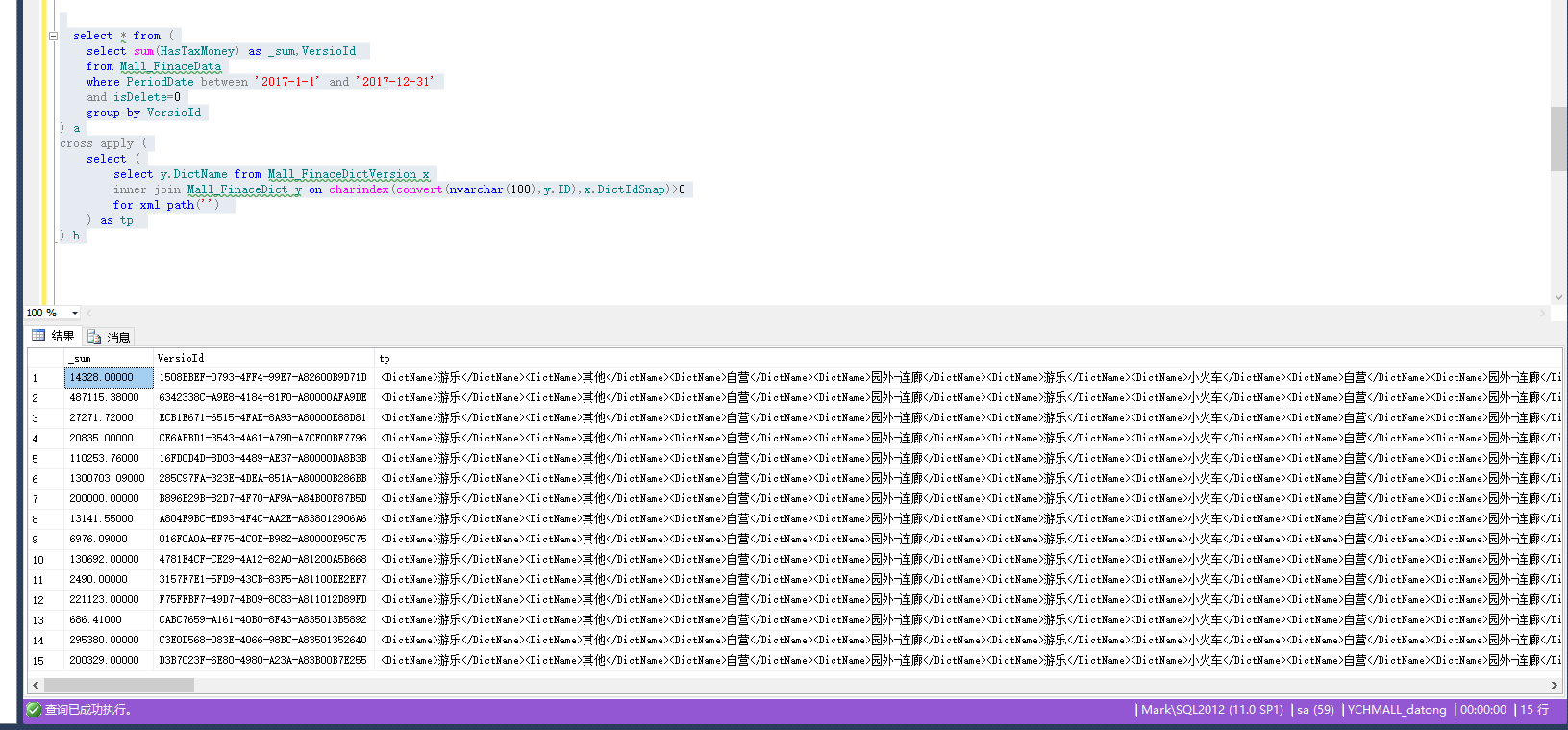
select * from (
select sum(HasTaxMoney) as _sum,VersionID
from Mall_FinaceData
where PeriodDate between '2017-1-1' and '2017-12-31'
and isDelete=0
group by VersionID
) a
cross apply (
select (
select distinct ''+y.DictName from Mall_FinaceDictVersion x
inner join Mall_FinaceDict y on charindex(convert(nvarchar(100),y.ID),x.DictIdSnap)>0
where y.DictName in ('自营','零售','游乐','收入','联营','水吧')
order by charindex(y.DictName,'游乐零售水吧自营联营收入')
for xml path('')
) as tp
) b


select * from (
select sum(HasTaxMoney) as _sum,VersionID
from Mall_FinaceData
where PeriodDate between '2017-1-1' and '2017-12-31'
and isDelete=0
group by VersionID
) a
cross apply (
select (
select y.DictName from Mall_FinaceDictVersion x
inner join Mall_FinaceDict y on charindex(convert(nvarchar(100),y.ID),x.DictIdSnap)>0
for xml path('')
) as tp
) b

SELECT CASE WHEN MFDV2.DictName=N'自营' THEN N'零售自营收入'
ELSE N'零售联营收入'
END AS Type
, SUM(HasTaxMoney) AS totalHasTaxMoney
FROM Mall_FinaceData AS MFD
CROSS APPLY
(SELECT TOP 1
DictName
FROM Mall_FinaceDictVersion AS MFDV
WHERE MFD.VersioId=MFDV.ID
AND EXISTS (SELECT 1
FROM Mall_FinaceDict
WHERE DictName IN ( N'自营', N'联营' )
AND MFDV.DictIdSnap LIKE '%'+RTRIM(ID) +'%')
AND EXISTS (SELECT 1
FROM Mall_FinaceDict
WHERE DictName=N'零售'
AND MFDV.DictIdSnap LIKE '%'+RTRIM(ID) +'%')) AS MFDV2
GROUP BY MFDV2.DictName;
