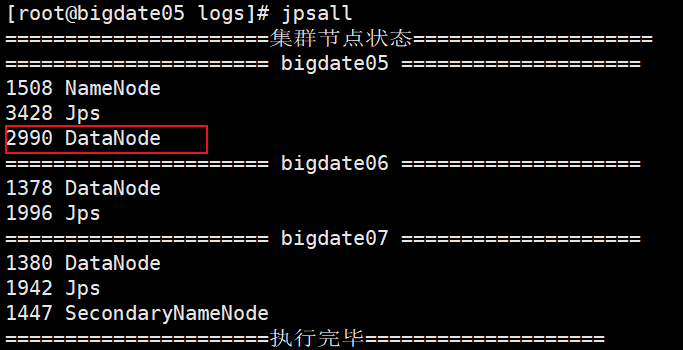
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
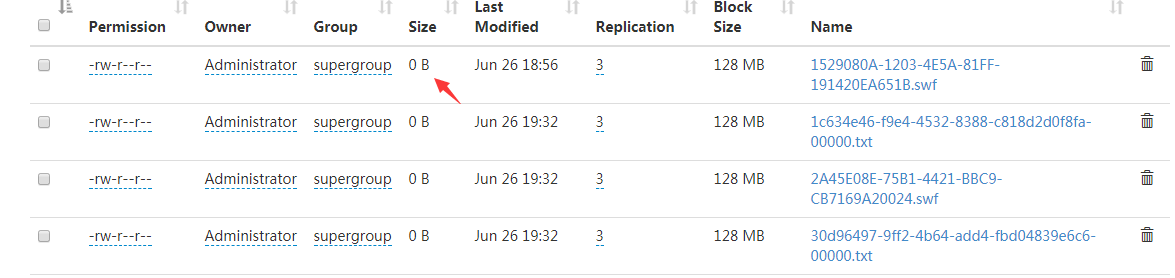
上传上去的文件大小是0
hdfs的配置:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubt:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>ubt:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.federation.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>ubt:9000</value>
</property>
<property>
<name>dfs.hosts</name>
<value>nn1</value>
</property>
</configuration>
java代码
public static void main(String[] args) throws FileNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ubt:9000");
conf.set("dfs.nameservices", "mycluster");
conf.set("dfs.ha.namenodes.mycluster", "nn1");
conf.set("dfs.namenode.rpc-address.mycluster.nn1", "ubt:9000");
conf.set("dfs.client.failover.proxy.provider.mycluster",
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
FileSystem fsys = null;
try {
fsys = FileSystem.get(conf);
} catch (IOException e) {
log.error("hdfs服务获取失败!");
}
//读取本地文件系统的文件,返回输入流
OutputStream out=null;
InputStream input = new FileInputStream("abc.txt");
try {
//在HDFS上创建一个文件,返回输出流
out = fsys.create(new Path("/abc.txt"), new Progressable() {
public void progress() {
System.out.print(".");
}
});
//工具类将in中的内容copy到out中
IOUtils.copyBytes(input , out, 4096, true);
} catch (IllegalArgumentException e) {
log.error(e.getMessage(), e);
log.info("参数错误");
} catch (IOException e) {
log.error(e.getMessage(), e);
log.info("上传错误");
}finally{
try {
input.close();
out.close();
} catch (IOException e) {
log.error(e.getMessage(), e);
log.info("关闭文件流错误");
}
}
}
报错如下:
第一段报错:
20:23:32.903 [main] DEBUG org.apache.hadoop.util.Shell - Failed to detect a valid hadoop home directory
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:326)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:351)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:2823)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:2818)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2684)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:373)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:172)
at com.jb.filesys.util.HDFSFileSystem.main(HDFSFileSystem.java:139)
20:23:32.921 [main] ERROR org.apache.hadoop.util.Shell - Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:394)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:387)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:80)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:2823)
at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:2818)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2684)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:373)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:172)
at com.jb.filesys.util.HDFSFileSystem.main(HDFSFileSystem.java:139)
第二段报错
org.apache.hadoop.ipc.RemoteException: File /guobao/FAA26584-946C-41F4-8E54-7B8EB4E6DD73.swf could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1814)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:265)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2563)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:846)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:510)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:503)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:871)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:817)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1889)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2606)
at org.apache.hadoop.ipc.Client.call(Client.java:1475)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy210.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy211.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1455)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1251)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:448)


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 我是因为DataNode 自己挂掉了 才出的问题
我是因为DataNode 自己挂掉了 才出的问题